


")
")




MovieMood
Problem & Motivation
We can all relate to the scenario of spending another night on the couch, endlessly scrolling through Netflix to find a movie. The algorithm is recommending the same type of movies - a few specific genres with plotlines you usually love. Oftentimes, this approach is great, but what if you’ve been feeling a little more adventurous this week and you’d like to try something unusual?
Major streaming services don’t take your emotional state into account when making recommendations and simply show you movies that you typically watch. And with so many streaming services available, it’s easy to get overwhelmed by all the options. In fact, studies show that streaming users spend an average of 18 minutes searching through content before finding something new to enjoy.
MovieMood hopes to cut that decision time to 5 minutes by tapping into users' moods from their curated music playlists. The average American spends 32+ hours/week listening to music. MovieMood aims to bridge the gap between music and movies, by giving users movie recommendations that align with their mood & music preferences, to create a uniquely personalized and curated multimedia experience.
Minimum Viable Product (MVP)
Our MVP allows users to upload their Spotify playlist via a CSV file, to instantly recieve movie recommendations.
Users can customize their recommendations using our optional filters for genre, ratings, and IMDB score, as well as learn more details about the movie such as plot summary, director, IMDB & Rotten Tomatoes scores, etc.
Once they upload their Spotify playlist, users can also learn more about how we generate their movie recommendations by viewing the taste clusters that our model identified within their playlist, and the mood & Spotify metadata for their taste clusters.
Data Sources
Movie Data: We sourced 30 years’ movie data from Wikipedia/OMDB and scraped several key features about each movie, including plot summary, director, release date, etc.
Music Data: Spotify’s API1 contains several audio features for a given song. For our project, we focused on danceability, acousticness, energy, instrumentalness, liveness, valence, loudness, speechiness, and tempo within a user’s exported playlist
Movie Soundtrack Data: To train our movie genre prediction (content) layer, we gathered soundtracks from the Spotify API for 110 high grossing movies2 that were action, comedy, drama, horror, romance, and sci-fi genres. We then labelled each song within a movie soundtrack one genre label.
Data Science Approach

For our primary mood modeling layer, as seen above, we focused on four moods (happy, sad, energetic, calm) that are based on psychologist Robert Thayer’s traditional model of mood3, dividing songs along lines of energy and stress. The MovieMood architecture, goes through the following steps.
- Movie Sentiment Scoring: Feed OMDB/Wikipedia movie data, including plot summaries and genre, through a sentiment scoring algorithm, assigning each movie a mood level, between 0 and 1, for the 4 moods
- Music to Mood Classification: Input user’s music playlist, which contains track-level audio metadata, and for each song, predict the likelihood of the same 4 mood levels. Cluster the playlist to account for potential variation in audio metadata. Finally, average the mood levels per playlist cluster.
- Bridging music and movies: For each playlist cluster within (2), calculate a cosine similarity between the averaged mood vector for the cluster and all movies’ mood vectors to get the closest distance movies, which will be 5 movies total. See diagram below for example.
- Content Layer: Input user’s music playlist, which contains similar track-level data as (2), and for each song, predict likelihood of 6 key movie genres (action, comedy, drama, horror, sci-fi, romance). Then, calculate median probability for each movie genre for the entire playlist. Finally, filter on top movie genres above a certain threshold.
- Filter Output From Mood Layer: Filter the closest distance movies in (3) for genres from (4), ensuring all five movies contain the correct genres.
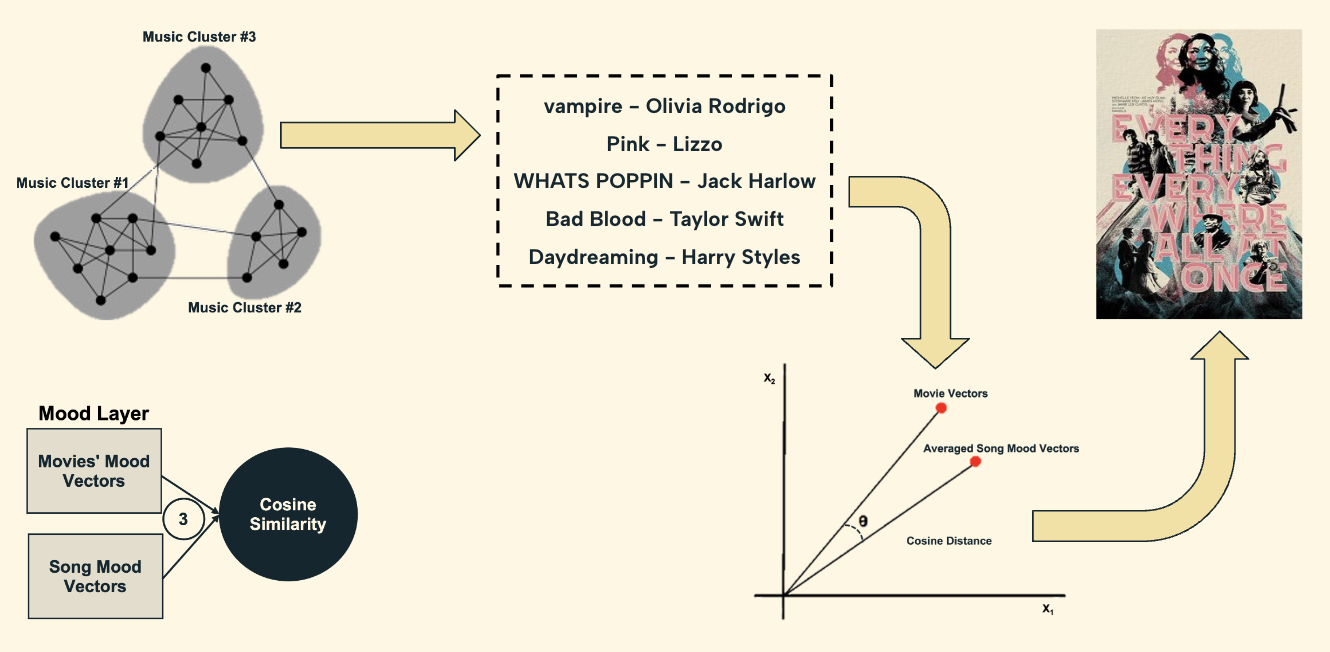
Evaluation
Our music-to-mood binary classifiers initially had polar or right-tailed distributions for each mood, so we introduced regularization and applied box-cox transformations to the outputted mood probabilities. In addition to quantitative evaluation metrics, we also manually evaluated our mood outputs to understand where exactly our model needed improvement. For example, our model gave very similar scores to chill playlists and to some horror movies – both had high values for ‘sad’ and a mix of energetic and calm. While these mood levels make sense for both a chill playlist and a horror movie, they simply don’t feel intuitive. This specific insight led us to implement the content layer (step 4) that filters out genres with low probabilities, and by doing this, we were able to take a model that works well in most cases, and turn it into something that works well in nearly all cases.
Beta Test
After we validated our primary mood layer, we recruited a test cohort of 20 people to run a beta test. Each participant uploaded a Spotify playlist that represented their taste, and received movie recommendations from our model. They then gave their opinions on the recommendations, as well as feedback on our website. Once we got their feedback, we made tweaks as necessary and sent a follow-up survey.
For our first iteration, we wanted to primarily assess the quality of the movie recommendations, solely based on mood, as well as get initial feedback on website functionality. As you can see, people rated their individual movie recommendations, as well as overall correlation with mood, with an initial median score of 3 out of 5.
After the first beta test, we improved our model and acted on the user feedback. We also incorporated dynamic clustering to identify taste clusters in a user’s playlist, as well as optional filters and additional movie details on the UI. After making these improvements, we re-polled the test cohort to get their feedback on the changes. The median score for user feedback on movie recommendations and correlation with mood rose to a 4 out of 5 (as opposed to the initial score of 3 during the first beta test).
Key Learnings & Impact
The main challenge we faced was bridging the gap between music and movie datasets with no obvious common features. In the end, we built the bridge using the emotions a user experiences while consuming both music and movies. We did this by extracting the mood vectors from the user’s music, and recommending the movies that were a closest match for that mood.
Once we built this mood bridge, we realized that wasn’t enough to fully account for all the complexity in a user’s music. We addressed this by building a multi-layered application, with the additional content layer that predicts movie genres from the audio features.
Finally, our last challenge was validating our end-to-end model without a properly labeled dataset, since we couldn’t simply make a train & test set to compare accuracy. So we got creative and designed a detailed user survey and put together a test cohort to validate the different stages of our model. Based on feedback provided at each development stage, we could assess movie recommendation quality and then incorporate the feedback for the next iteration.
Acknowledgements
- Capstone Instructors, Todd Holloway & Joyce Shen
- NYU Professor & Netflix Prize Winner, Chris Volinsky
- MIDS Alum, Max Eagle
References
- https://developer.spotify.com/documentation/web-api/reference/get-audio…
- Ma B, Greer T, Knox D, Narayanan S (2021) A computational lens into how music characterizes genre in film. PLoS ONE 16(4): e0249957. https://doi.org/10.1371/journal.pone.0249957
- E. Thayer, Robert (1989). The Biopsychology of Mood and Arousal. Oxford University Press USA.
Course
Data Science 210. Capstone , Fall 2023More Information
