


")
")




Pandemic Loan Outlier Detection and Indicators (PLODI)
Introduction
To support businesses during the COVID-19 pandemic, the US Small Business Administration (SBA) disbursed $1.2T of loans, which were backed by the US government, under the Paycheck Protection Program (PPP) and related programs. Due to the rapid pace at which these loans were processed many normal risk practices were relaxed and consequently many instances of fraud have been identified with estimates of fraudulent loans ranging from $100B-$200B (1 Link here). In this project we developed machine learning models to identify potentially fraudulent PPP loans, pinpointed key fraud risk factors, and ranked all loans based on their risk factors. This ranking can guide further development for identification of fraud indicators and investigation priority for regulatory agencies, guidance for loan screening for future loan programs, and supports open access to government spending for journalists and interested public individuals.
Data & Modeling
Our primary data set consisted of PPP loan data released by the SBA and included approximately 9.1M PPP loans (Link here). We utilized USPS address lookup to determine if an applicant’s address was valid under the theory invalid addresses could indicate suspicion. Census data by region and industry was used to determine normalized implied pay for 2019-2021(Link here). We reviewed and labeled 108 adjudicated DOJ cases and extracted 614 names yielding 752 unique loans. We assumed that a loan is “suspect” if it’s associated with one of the prosecuted cases (2 Link here). Due to licensing and republication concerns, we are only providing links to the original sources.
We assume a true fraud rate of 8% as estimates range from $70B-$200B (1) of the $1.2T disbursed. All models are trained/tested on ~9.4k loans, via downsampling of the non-case related loans, and assumed to be non-suspect. We elected to downsample our data due to the imbalance of prosecuted case labels compared to the unlabelled full loan data set. We performed a Train and Test split of 80% and 20% respectively. Given prosecuted cases are positive loan labels but remaining loans are unknown status and the goal of our project to focus on prioritizing cases for investigation, we weigh Recall (Sensitivity) and Negative Predictive Value as primary measures for MVP model selection. Based on the results from our test data, we selected XGBoost as our champion model as it outperformed relative to the other supervised and semi-supervised models we tested, which is consistent from prior published outlier detection benchmarks (3 Link Here). For more information on our model’s test results, please see the attached presentation (Link here).
Results & Impact
When using our champion XGBoost model and looking at the most suspicious loans, where we sort and cap statistical review on the top n samples, our model has very strong performance with the top 5-16% of loans getting correctly classified at rates of 98-89% respectively. Given the scale of the PPP loan program, machine learning could provide a ranking of fraud risk to guide expert investigative review.
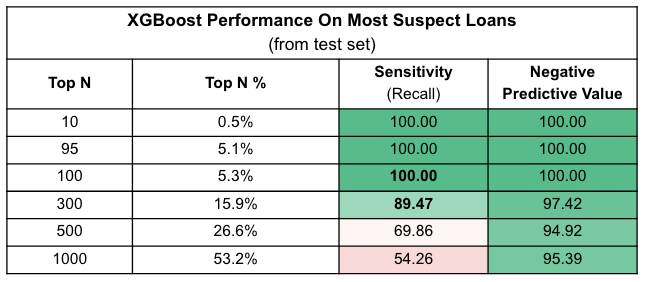
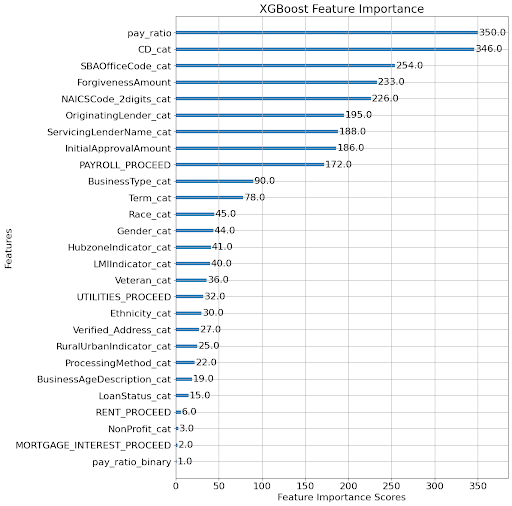
The most important features for our champion model are implied employee pay measures and location. Implied employee pay as measured by pay ratio is the most important feature while geographic information (cd_cat, or congressional district, and SBA office code) are also highly important. Suspicious loans tend to be clustered by geography, due to how cases were prosecuted, so the importance of this feature may not generalize.
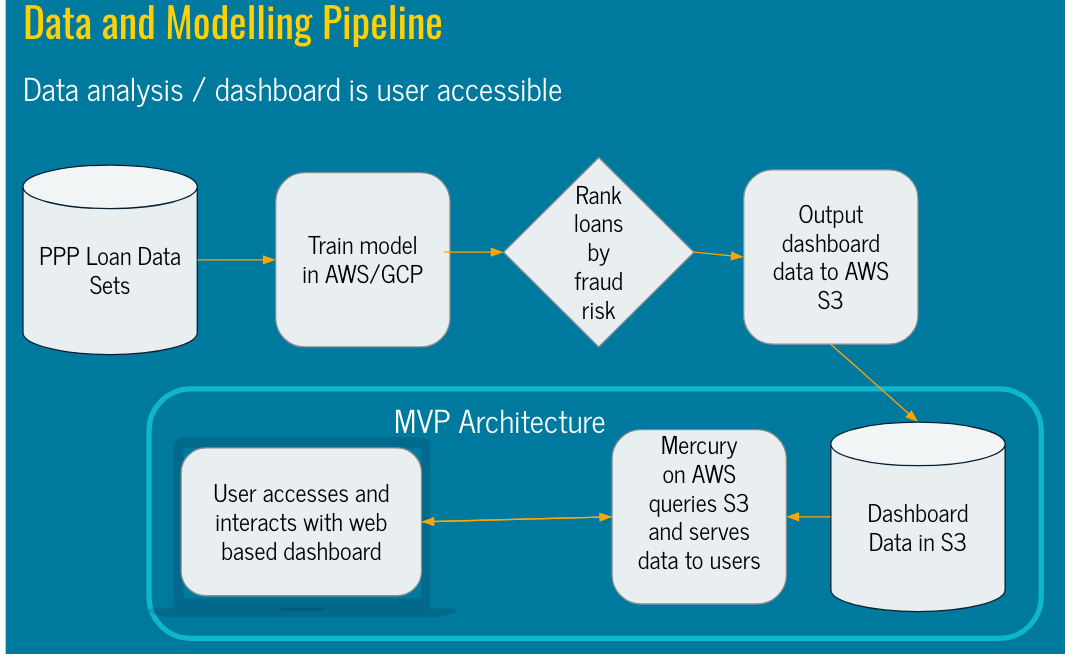
MVP Dashboard for Ranked Data & Architecture
Our MVP consists of a landing page (Link Here) that hosts a dashboard presenting ranked loan data with key features across the full PPP loan data set (Link Here), in which we provide two rankings suspicion_rank and suspicion_rank_weighted. These are derived from the predicted probability of suspicion and the probability of suspicion combined with the loan amount. We created a weighted ranking to account for differing loan amounts under the theory that regulators may want to focus on higher value loans for the purposes of maximizing recovery. A brief slideshow also distills our presentation for any visitors to the website (Link Here), and a data dictionary for the source features used in our modeling process is also available (Link Here). Separate GitHub repository links to the overall project and MVP dashboard are provided.
We leveraged AWS and GCP for data cleaning, modeling, and ranking. We then saved our loan level results to an AWS S3 bucket for our dashboard to easily access. To create our dashboard, we opted for a python based framework called Mercury to query and display our champion model results.
Acknowledgments
We’d like to thank Daniel Aranki and Puya Vahabi, our course instructors, for their excellent guidance and feedback throughout the semester. We also want to thank Dakota Sky Potere-Ramos for working with us to identify and mitigate data privacy and ethics risks. Lastly, the authors of Did FinTech Lenders Facilitate PPP Fraud?John M. Griffin, Samuel Kruger, and Prateek Mahajan as many of our engineered features take inspiration from their work.
References
1. U.S. Small Business Administration OIG. (2023, June 17). Covid-19 pandemic EIDL and PPP loan fraud landscape. COVID-19 Pandemic EIDL and PPP Loan Fraud Landscape. https://www.sba.gov/sites/sbagov/files/2023-06/SBA%20OIG%20Report%2023-…
2. U.S. Department of Justice Criminal Division (2023, August 2023). Fraud Section Enforcement Related to the CARES Act. https://www.justice.gov/criminal/criminal-fraud/cares-act-fraud
3. Han, S., Hu, X., Huang, H., Jiang, M., & Zhao, Y. (2022). Adbench: Anomaly detection benchmark. Advances in Neural Information Processing Systems, 35, 32142-32159.
Course
Data Science 210. Capstone , Fall 2023Video
If you require video captions for accessibility and this video does not have captions, click here to request video captioning.