


")
")





signlanguage.io
Building Inclusive Communities for All
Our mission is to break the communication barriers for hearing and speaking impaired communities by creating an effective and accessible sign language interpretation solution.
Unlike spoken language, sign language is multi-dimensional and relies on both manual and non manual cues. It involves hand shape, hand orientation, location, movement, gestures and body posture, facial expressions, lip movements. Sign language has its’ own grammar, linguistic rules. The states across the USA does not conform to a standard form of ASL as the teaching standard, which makes it even more challenging to understand and follow through.
Approximately more than half a million people across the United States use ASL as their native language and communicate using it. Off those impacted, 3.8% are deaf and 42.9% are not part of the labor force.
ASL interpreting service is very expensive. On average, hiring interpreters to be present physically in meeting or client conversations can cost ranging from 50 to 145$ an hour. Travel cost comes additionally on top of the interpreting service and needs to be paid by the requestor. In most cases, it is necessary to book the interpreter for minimum 2 hours period.
There are only 10,253 certified ASL interpreters across USA and Canada although ASL interpretaion is widely used across various sectors and often required by law.
ASL interpretation is in high demand with limited access. So we are building a machine-learning enabled interpretation and translation solution to increase ASL access.
Data Source
We have collected data both from web and our own recording. The web scraped aquired data can be gif or regular youtube video or youtube shorts or embedded video. The generated data are our own recorded data.
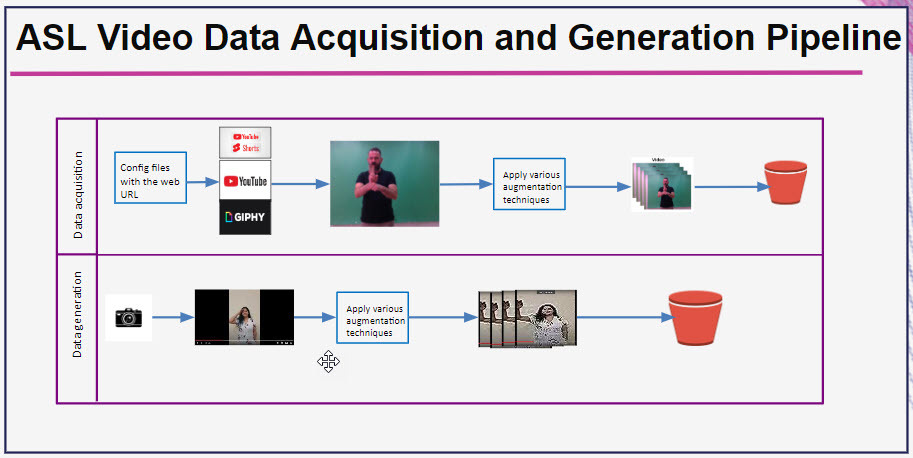
Data Engineering
Both our aquired data and generated data are processed as mp4 video files. We have applied video augmentation techniques like adjusting brighness, horizontal or vertical flip, gamma adjustment, rendering it fast or slow. Our data are stored in Google drive.
Scenario Setting
| Scenario | Conversation Text | Isolated Signs |
|---|---|---|
| Classroom | Hello teacher, thank you, love the class. |
|
We have done our remaining machine learning experiments referencing the above data scenario.
Machine Learning Experiments
We have experimented with several machine learning algorighms:-
- Mediapipe and LSTM
- ConvLSTM
- Conv2plus1D
- MoViNet
In our experiments, we have seen Mediapipe-LSTM solution was very slow and did not generalize well. ConvLSTM method did not work well either. We have gotten good performance from Conv2plus1d and MoViNet.
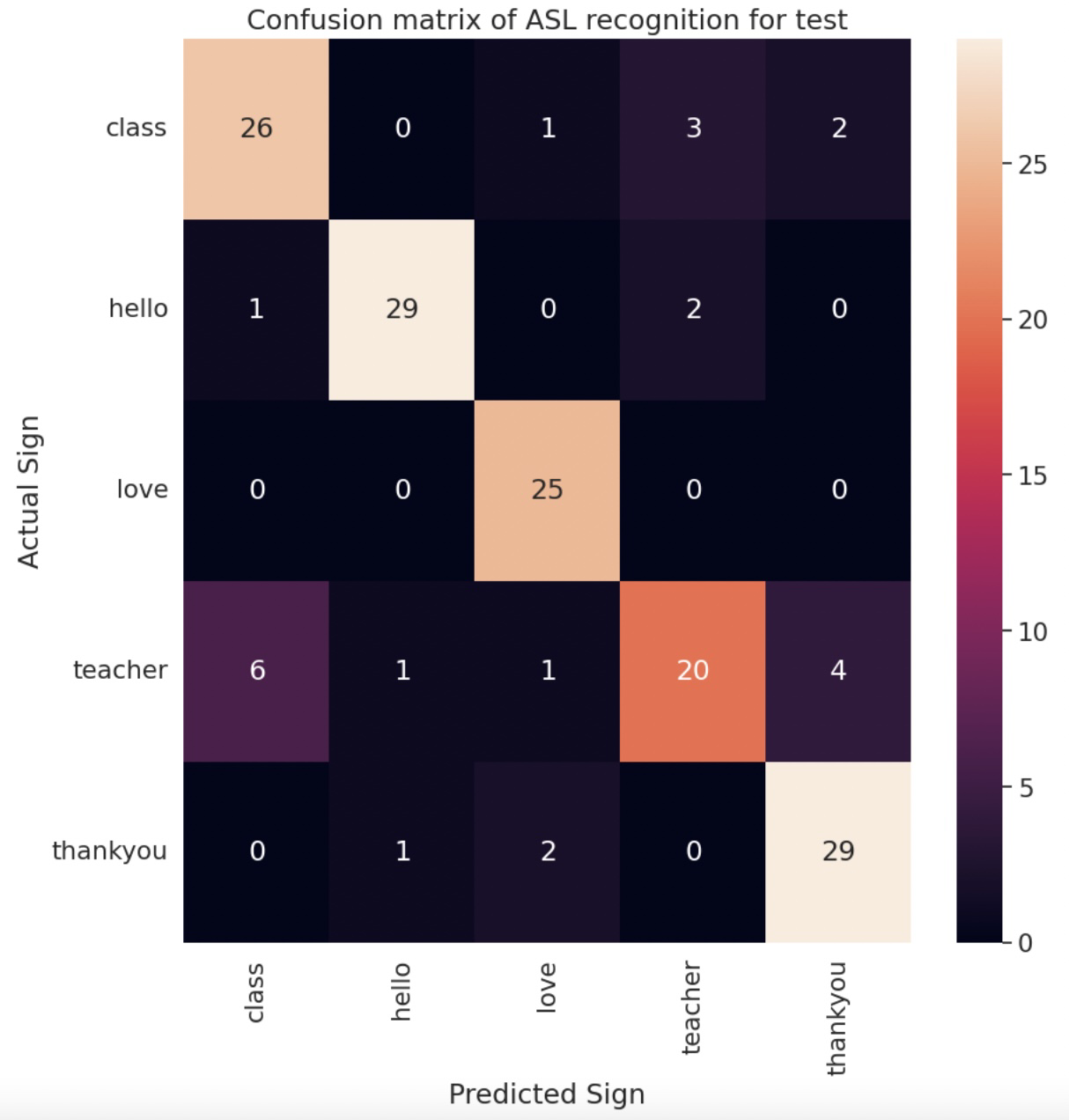
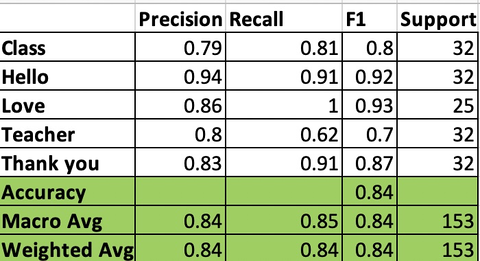
We have focussed more on Conv2plus1d and MoViNet for 5 and 8 signs using different hyperparameters and MoViNet a1 model performed best for isolated ASL recognition.
Below is the performance statistics for a1 model:
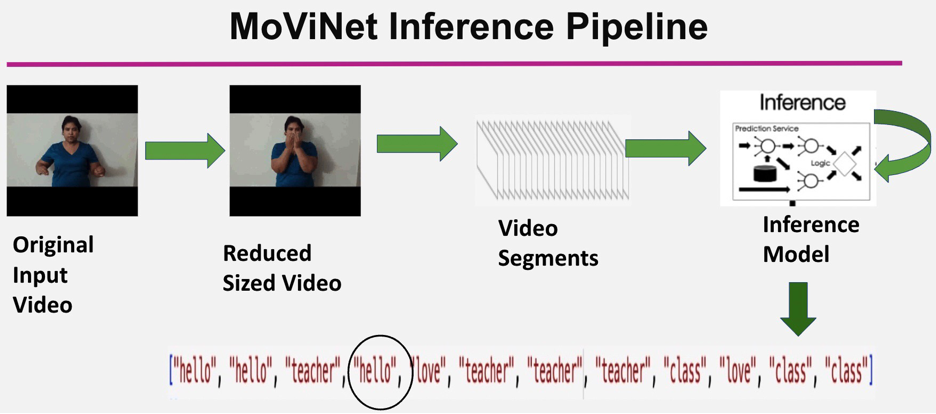
MoViNet Inference Pipeline
We have trained our model using isolated sign languages and want to test the performace in the continous setting with a conversation sign video input.
In the application, the user uploads a conversational video clip. We process the video to a reduced video by dropping the motion less frames. This has an advantage. It passes smaller data chunks over the network for iterative model inference call and runs lot faster.
The reduced frame video is further split into smaller video segments and we call the inference model iteratively for each video segments and each video segment returns the predicted label.
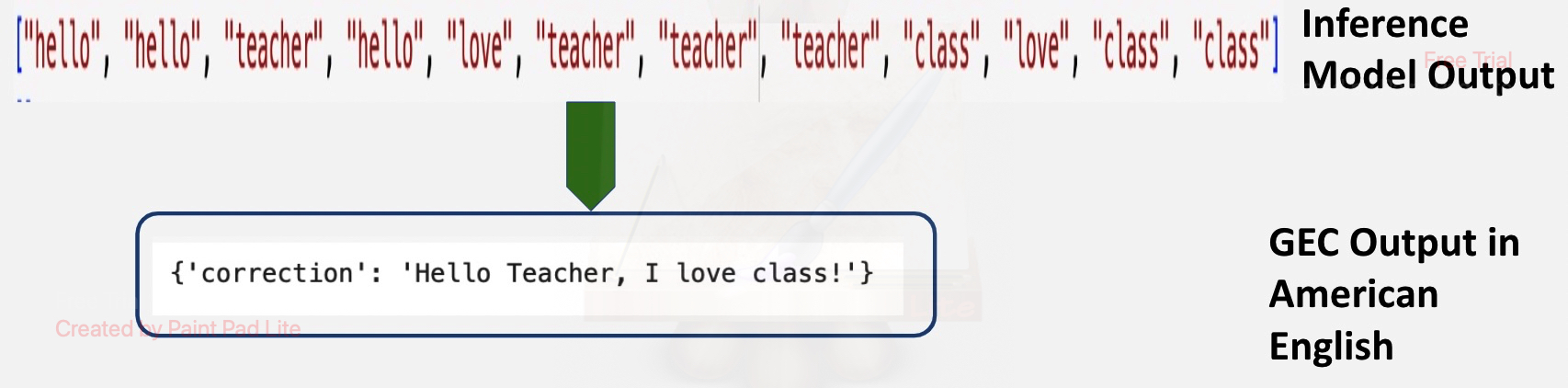
Grammar Correction Code
The inference model transcribes the English gloss, which is not yet a grammatically correct sentence. Using finetuned-llama-2-70b grammar correction module we produce grammatically correct English sentence.
Multilingual Translation
We thought that English may not be the first language of for all our audience, so if we can translate to few other popular languages, it would be helpful. So we have used facebook/m2m100_418M model to generated the English output to French, Spanish and Hindi.
![]()
Key Learnings
In our experiments we have few major learnings:-
- Data is the key. Quality of the data dictates the model performance.
- Variability of the signers can change the model performance a lot.
- Clear background with no background objects provide better model performance.
- Lower learning rate along with lot of training time produces better results.
- This is a resource hungry process. We need lot of data to get good results.
- Inference model with trained weights do not work same way as simple model save or model save weights. Rather the model weights need to be saved in tflite format to be used later.
Future Work and Roadmap
- We want to extend our work with new signs and test the model performance.
- We would also like to evaluate model performance in a continuous setting using both signs and finger spelling.
- We want to extend the model architecture to adapt to other sign languages like Indian Sign Language.
- We want to test the performance in the mobile application as well.
Acknowledgements
We are extremely grateful to our instructors Joyce Shen and Kira Wetzel, Mark Butler, Alex D for all their support, guidance encouragements and references. In addition, we are thankful to our teaching assistants Prabhu, Dannie and Jordan for their time help in various project phases. We also want to thank subject matter expert Jenny Buechner and Haya Naser for their time and guidance and our classmate Olivia Pratt from DATASCI (Data Science) 231: Behind The Data: Humans And Values for her in depth analysis about model fairness. Finally, we are grateful to our friends and families for their unwavering support, guidance, encouragement to reach to the finish line.
Course
Data Science 210. Capstone , Fall 2023Video
If you require video captions for accessibility and this video does not have captions, click here to request video captioning.