


")
")





Scraps To Scrumptious
Problem and Motivation
In today's fast-paced world, many individuals and families struggle with meal planning and cooking. The process of finding suitable recipes based on available ingredients and specific dietary needs can be time-consuming and stressful. This often leads to food waste as ingredients spoil before they can be used, costing households an average of $1500 per year. Additionally, the lack of personalized recipes can make it difficult for people with specific dietary restrictions or preferences to enjoy a variety of meals.
The Scraps2Scrumptious project is motivated by the desire to make nutritious cooking easy and accessible for everyone, regardless of their dietary needs or pantry limitations. By leveraging the power of AI, we aim to provide personalized meal suggestions and ingredient substitutions that maximize pantry resources and cater to unique tastes and dietary needs. This not only helps to reduce food waste and save money but also improves the quality of life by ensuring that everyone can enjoy delicious, homemade meals. Furthermore, by promoting healthy eating and reducing food waste, we contribute to the well-being of our users and the environment.
Data Source & Data Science Approach
Dataset
Food.com Recipes and Reviews from Kaggle. The recipes dataset contains 522,517 recipes from 312 different categories collected from 1999-2020. This dataset provides 28 attributes about each recipe such as cooking times, servings, ingredients, nutrition, instructions, and more.
Vector DB Document Creation
Our recipes are represented by a documents Vector Database for use in the retrieval process of a RAG-based system. The documents are structured by selecting attributes for metadata and concatenating several key features together to serve as the page content. When a query is made, the primary comparison is performed against the “page content” containing our combined feature set of each recipe. Certain elements of our retrieval chain may take advantage of the available metadata attached to each recipe.
Retrieval
RAG optimizes the output of Large Language Models (LLM) by referencing a specified knowledge base and retrieving the most relevant information for the LLM context window. We explored various Retrieval techniques with Langchain:
- Cosine Similarity Search - Similarity score derived from the angle of a vector embedded user query and document vector database.
- Maximum Marginal Relevance (MMR) - Expands upon cosine similarity by employing a re-ranking technique to find a balance of relevant and diverse items in response to a query.
- Self-querying LLM with Structured Output - Using OpenAI as the LLM, take the query and construct a filter and parser that optimizes the recipe selection.
- Cross Encoder Reranker - Enhances the quality of the generated responses by reranking them based on relevance and coherence, ensuring that the final output is the most appropriate answer to the user's query.
The final retrieval method is chained together. We experimented with various parameter types and system prompts to create the final chain:
- MMR - Provide a pool of diverse and relevant documents to consider
- Self-querying LLM - Semantically validate user requirements against each recipe and generate a structured query to filter out recipes within the provided MMR pool
- Cross Encoder Reranker - Rescore the remaining documents with higher precision to pass the best recipe to our Chat LLM
Augmentation with Tool Calling Agent
Tool calling allows a model to detect when one or more tools should be called and respond with the inputs that should be passed to those tools. In an API call, you can describe tools and have the model intelligently choose to output a structured object like JSON containing arguments to call these tools. The goal of tools APIs is to more reliably return valid and useful tool calls than what can be done using a generic text completion or chat API. We implement 2 tools:
- Web Search - in situations where the user request cannot find relevant documents in the vector database or the user asks for an ingredient substitution, the LLM has access to a Google search agent to look up the answer.
- Query Augmentation - the chat LLM system prompt allows the LLM to alter the original user query and re-query the retrieval chain. The chat LLM will retain this information for comparison and present the user with the best result from all the queries made on behalf of the user.
Generation
- Gatekeeper Questions - A final layer of gatekeeper questions is presented to the LLM to evaluate if the recipe violates any of the user’s accommodations in the recipe. If the recipe passes these questions, then the recipe is presented to the user.
- Chat History Retention - Allows the user to re-query the LLM to modify preferences or add substitutions by injecting the chat history into the follow-on context window. This allows the user to fine tune their recipe to exactly what they like.
- Dynamic Suggestions - After a recipe is presented, we added a series of clickable suggestions that allows the user to modify the existing recipe. These are dynamically generated based on the content of the query and system response.
System Architecture
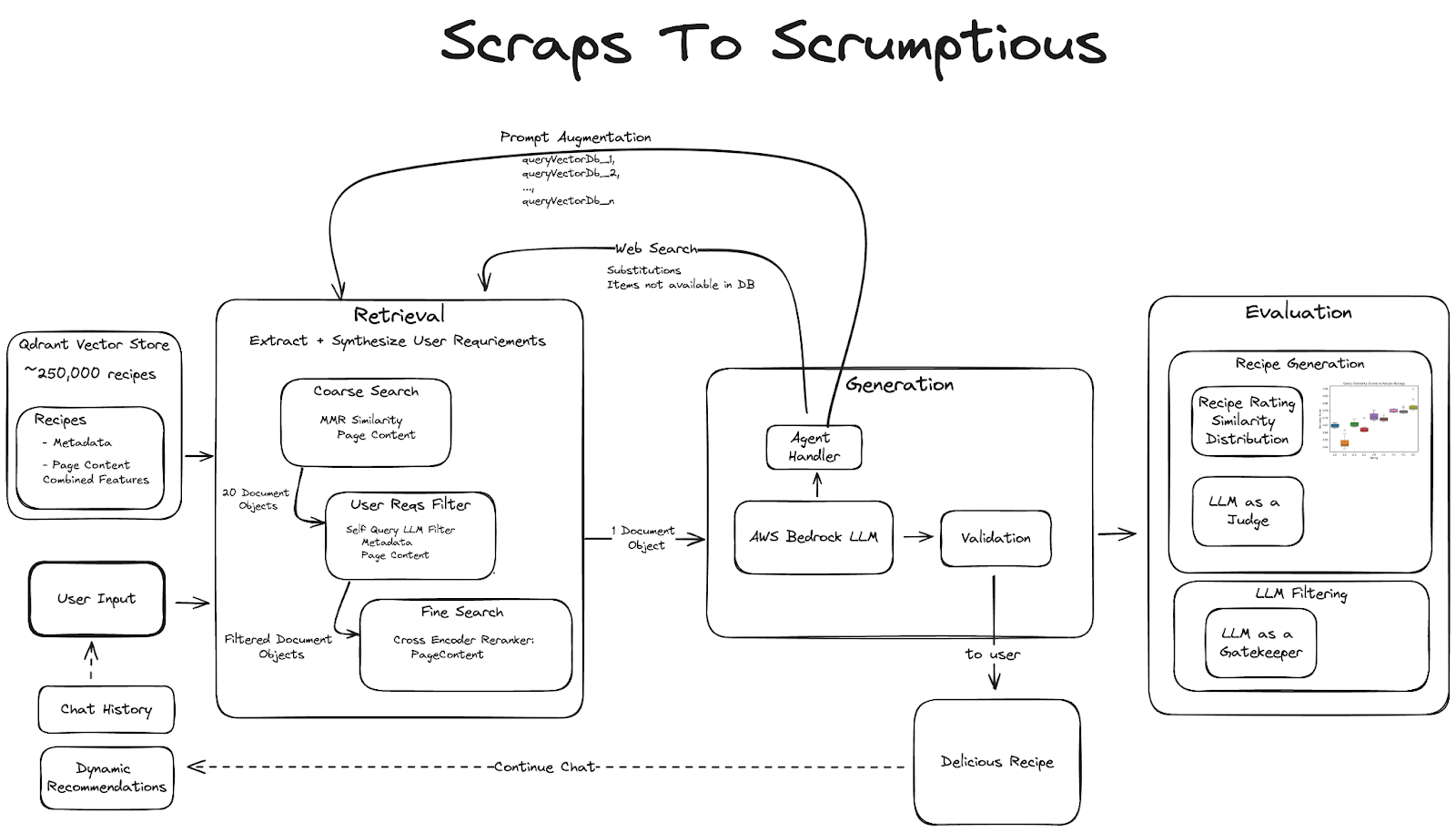
Evaluation
LLM as a Judge
“LLM as a Judge” refers to the concept of using a Large Language Model as an adjudicator or decision-maker in various applications. We created a series of test queries to evaluate our hyperparameter tuning. We made use of this concept in two ways:
- LLM as a Judge - Given a rigid set of criteria that defines what scoring across multiple categories, rate the recipes across the different configuration generated the outputs.
- LLM as a Gatekeeper - Given a list of conditions and validation tests, ensure that the generated outputs adhere to the user requirements, dietary restrictions, allergies, and any other provided restrictions. Provide a yes or no, and reasoning, for why a generated response complied with a given test query.
Similarity Comparison
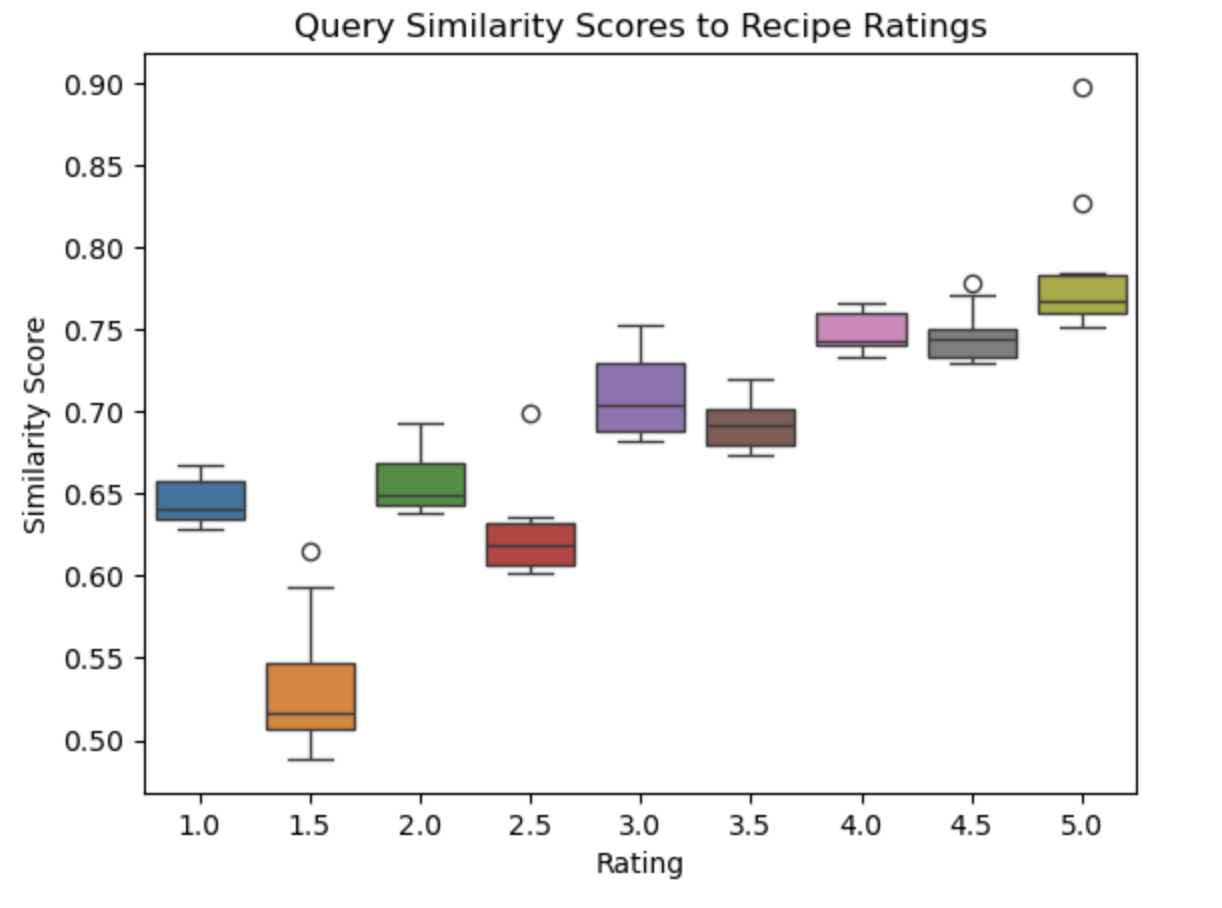
Recipes are quite subjective and sensitive to changes that a LLM may not be reasonable towards. In order to gauge how “good” our generated response may be, we take the generated response of a given test query, and determine which recipes it is most similar to within our database. We perform this similarity for the top 10 most similar recipes under each aggregated review score (1 to 5 in increments of 0.5) to gauge how likely our untested recipe is to be good.
An example of a “good” recipe follows below. The highest similarity score are associated with recipes that have high user ratings, while the lowest similarity scores are associated with low user rated recipes.
Key Learnings & Impact
Implementation of a complex RAG system with additional layers for optimizing the LLM context window with relevant documents, LLM agents, and usage of LLM as a judge.
We implement some of the best offerings available within the GenAI field to enhance access to healthy and sustainable meal options. Our innovative chatbot curates personalized recipes, helping users make informed choices that reduce food waste and promote overall well-being.
Acknowledgements
- Joyce Shen
- Kira Wetzel
- Mark Butler
- Robert Wang
- Capstone summer 2024 section 8