


")
")


")

Enterprise Code Generation
Problem & Motivation
Code completion models represent a large and growing opportunity. There are over 20 million professional software engineers in the world and code generation tools potentially increase their productivity by dozens of percent. However, most work in this area involves training on open source code bases and performing evaluations on highly structured code competition problems. This is not realistic for the enterprise setting where there may be thousands or millions of code files which differ greatly from the open source training set, and evaluation is not so straightforward. Our goal is to bridge this gap and create a framework to enable the fine-tuning and deployment of code generation models on proprietary enterprise code bases.
In our preliminary user research we found four specific value adds:
- Bringing in code from other portions of the codebase correctly
- Generating highly repetitive components of the codebase
- Validating the effectiveness of the model versus the baseline
- Self-hosting the train, test, and evaluation to ensure no proprietary code leakage
Technical Approach
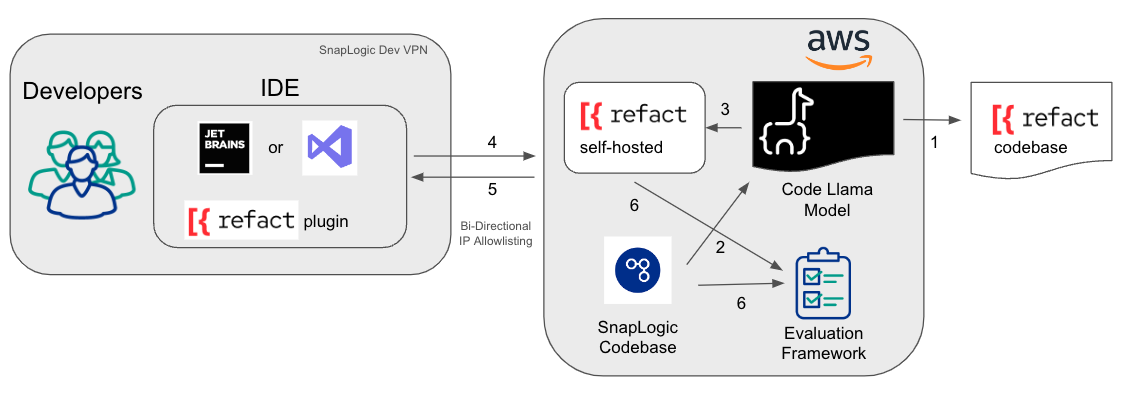
Our solution is a self-hosted instance of the open source Refact framework that is deployed to SnapLogic (our corporate partner) developers via their IDEs. Refact is an existing tool for fine-tuning a code completion model and deploying it to an IDE via a plugin. SnapLogic is a 200 employee PASS/SAAS company. The diagram above shows the tools utilized in and steps of our solution:
- Added Refact support for Code Llama fine-tuning. Refact already has other models for fine-tuning but Code Llama is one of the newest and most state of the art code generation models
- Fine-tuned Code Llama on the SnapLogic codebase
- Stood up a self-hosted version of Refact with the fine-tuned model as an endpoint
- SnapLogic developers installed the Refact plugin to their IDEs which automatically generated requests as they were writing code
- The endpoint responded with generated code completions
- We automatically evaluated the performance of our fine-tuned model on the SnapLogic codebase using standard domain metrics (CodeBLEU, Pass@K)
Results
In both technical metrics and user feedback we found that the fine-tuned model performed better than the baseline model, but still fell short of practical usability.
In a survey, the SnapLogic software developers rated the fine-tuned model as statistically significantly more useful and conformant to local conventions than the baseline. However, even the fine-tuned model scored a median 3 out of 7 for usefulness and conformance. The developers thought some of the suggested code properly aligned to the conventions of the codebase but also found many issues. Some qualitative feedback on individual generated responses:
“It doesn't mesh 100% with the existing code which is somewhat of a problem, but I think this would move things in a good direction.” - SnapLogic Software Developer
“I wouldn't want to see this code completion, the number of nulls is staggering.” - SnapLogic Software Developer
On the technical side we found that the code written by the fine-tuned model passed unit tests (Pass@1) about 3% more often than the baseline model. Still, even the fine-tuned model only managed to pass 34% of the unit tests. CodeBLEU, a measure of the syntactic similarity between two pieces of code, was similar in both models.
Key Learnings
Our main learning was that our code generation model showed promise but still has a way to go before It is a value add for software engineers. Initial results, however, are solid and fine-tuned models have a noticeable impact compared to generic ones, both from quantitative and qualitative perspectives. We believe with a larger but also more carefully curated training set, a larger model, and more user feedback set we could improve our results further.
Acknowledgements
The team would like to acknowledge the Refact team for working on the open source library that was used to fine-tune, the Snap team from Snaplogic for contributing their time and expertise, as well as Greg Benson from the University of San Francisco for initial guidance for how to get started.
Course
Data Science 210. Capstone , Fall 2023