

")







Restor-AI-tion
Problem & Motivation
The issue at the heart of our project lies in the legibility of ancient Japanese texts. Spanning over a thousand years of Japanese history, premodern Japanese literature and historical documents were penned in Kuzushiji, a script now legible to less than 0.01% of modern Japanese speakers. This renders a myriad of texts, ranging from calligraphy to culinary manuscripts and family records, inaccessible to the majority of today's population. While painstaking efforts by experts are underway to manually restore and convert these texts to standardized scripts, the process is time-intensive. Enter the future of historical exploration with Restor-AI-tion, a groundbreaking initiative ready to seamlessly transform this arduous journey into an automated process. With just a few clicks, what used to take years can now be accomplished in mere minutes.
Our motivation goes beyond the technical challenge. At the core of Restor-AI-tion is a deep-seated desire to preserve Japan's rich history and culture. We aim not only to make these historical texts accessible but to ignite a renewed interest in ancient Japanese customs and practices. The transformative power of Restor-AI-tion lies in its potential to enhance legibility and the overall quality of written texts, making this treasure trove of literature available to diverse groups, from scholars delving into academic research to everyday individuals exploring their cultural heritage.
Data Sources
The datasets noted below collectively form a diverse and comprehensive foundation for our project, enabling the exploration and understanding of Kuzushiji in various contexts.
1. KMNIST K49 (Phonetic Hiragana Dataset)
- Consists of 49 classes, each representing a single hiragana character or iteration mark.
2. KMNIST KKanji (Symbolic Kanji Dataset)
- Consists of 3832 classes, each associated with a single kanji.
- The dataset showcases different Kuzushiji variations of each kanji, resulting in a highly imbalanced dataset with varying examples per class (ranging from nearly 1800 to only 1 example per class).
3. Nise (Main Dataset)
- Encompasses full pages from 44 classical Japanese texts written in Kuzushiji.
- Text genres range from comic strips and literary fiction to seasonal cookbooks.
- The dataset includes bounding boxes for each character on the page, along with its corresponding modern character.
Data Science Approach
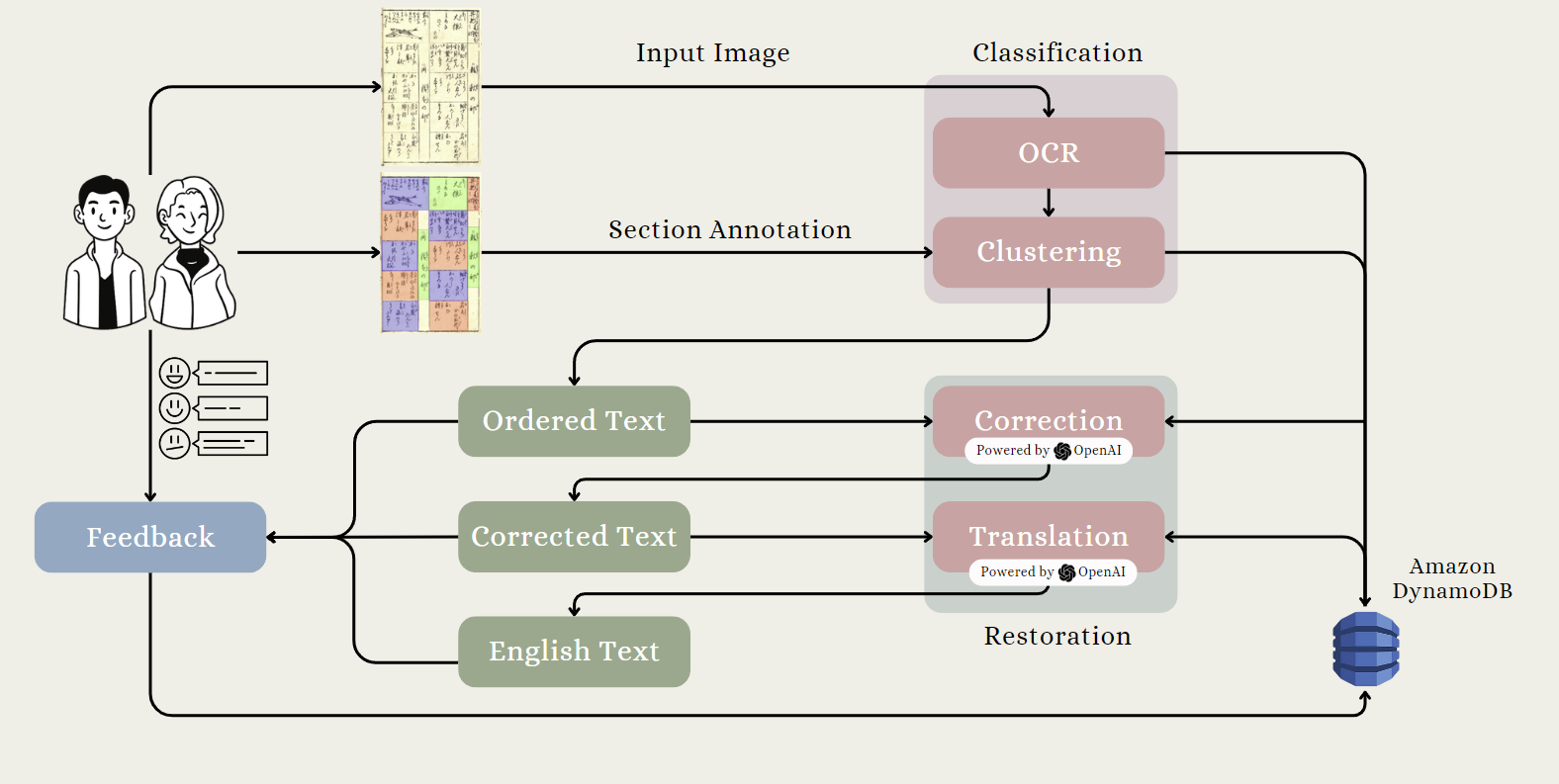
1. Character Recognition with Hanya’s OCR
- User Input: Start with user-submitted images of Kuzushiji text.
- Hanya’s OCR with Deep Learning Models: Leveraging Hanya’s OCR, our model seamlessly identifies bounding boxes for each intricate Kuzushiji character. Powered by state-of-the-art models including CenterNet and MobileNetV3, we efficiently convert these ancient characters into their modern Japanese counterparts.
2. Reading Order Determination With K-Means Clustering
- User-Guided Reading Order: Users contribute to the process by drawing bounding boxes, establishing the correct reading order for the artwork.
- OCR-Driven Clustering: Extracting OCR-recognized characters within user-defined bounding boxes, we apply K-Means clustering with a custom distance metric.
- Spatial Refinement: Merging centers within 2 standard deviations of OCR bounding boxes refines our clusters spatially, enhancing accuracy.
- Iterative Optimization: For precision, we iteratively recompute cluster centers until convergence.
3. Text Correction and Translation with OpenAI API
- Organized Reading Order: Characters, now in the correct reading order, set the stage for the next steps.
- ChatGPT's Linguistic Expertise: Leveraging GPT 4.0 API, we generate corrected interpretations of the archaic text, enriching the narrative.
- Multilingual Transformation: The ChatGPT API takes the lead again, translating the text into English, transcending language barriers.
Evaluation
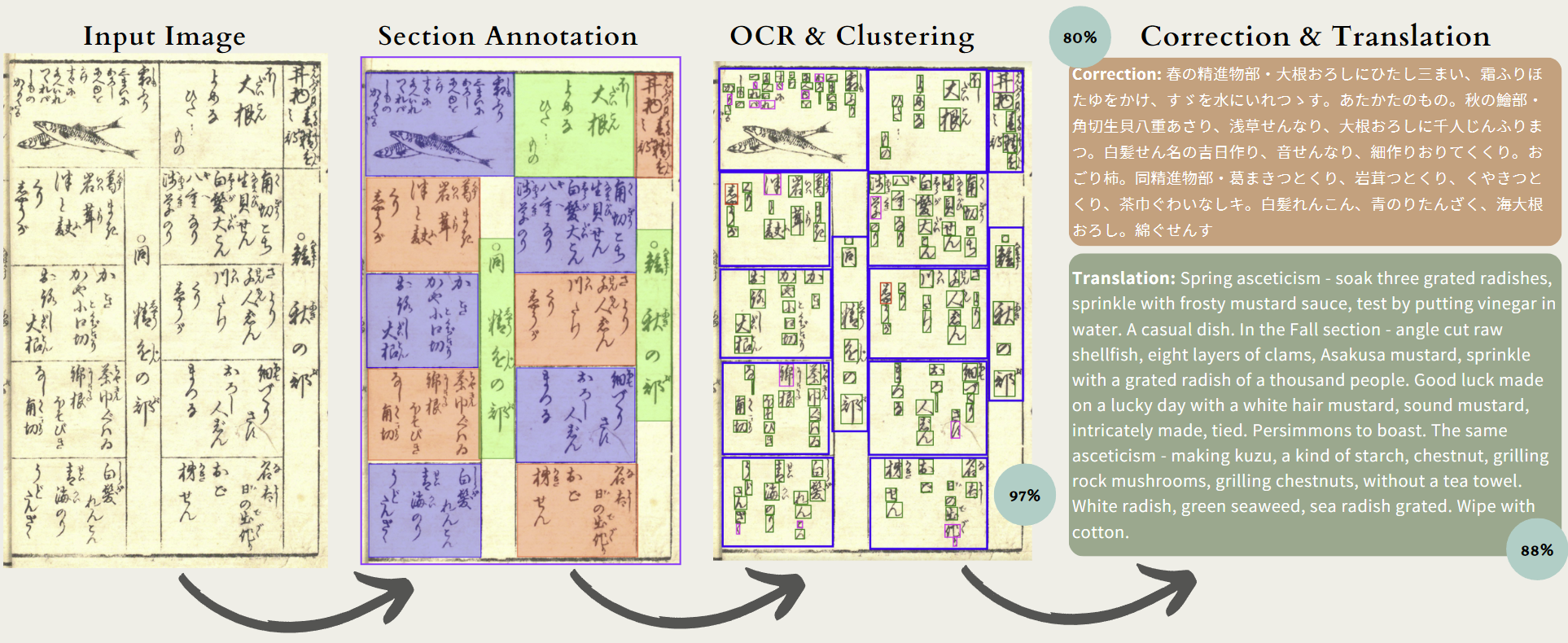
OCR Accuracy Assessment
- Visual Feedback for Users: Users receive visual feedback through bounding boxes colored for quick interpretation:
- Green: Probability >= 0.9 – High Confidence
- Magenta/Pink: Probability >= 0.5 and < 0.9 – Moderate Confidence
- Red: Probability < 0.5 – Low Confidence
Reading Order and Clustering Quality
- Bleu Score: To evaluate the quality of our reading order and clustering output, we use the Bleu score, a metric commonly applied in natural language processing tasks.
- Objective Measurement: The Bleu score provides an objective measure of the similarity between the predicted reading order and the ground truth, allowing us to refine and optimize our clustering approach.
Text Correction and Translation Confidence
- ChatGPT Confidence Scores: The OpenAI (GPT 4) API supplies confidence scores for both the corrected interpretation and translation.
- User Assurance: Users are provided with confidence metrics, ensuring transparency and reliability in the transformed text.
Key Learnings
- Learning how to seamlessly integrate traditional aspects of ancient Japanese texts with cutting-edge technologies, bridging the gap between the past and present.
- Discovering the importance of involving users in the reading order determination process, showcasing the effectiveness of user input in refining the output.
- Understanding the nuances of spatial relationships in Kuzushiji characters and refining clustering techniques iteratively for improved accuracy.
Impact
- Enabling the preservation of Japan's rich history and culture by making ancient texts accessible to a wider audience.
- Providing a valuable resource for educators and students interested in exploring ancient Japanese texts, promoting understanding of the language's evolution.
- Empowering users with a tool that not only deciphers ancient texts but also involves them in the process, making historical exploration an interactive and enriching experience.
Acknowledgments
We extend our deepest gratitude to Professors Puya Vahabi and Danielle Cummings, whose guidance and feedback have been instrumental throughout our entire journey. Their commitment to fostering a dynamic learning environment has been evident in every piece of advice, critique, and encouragement they've shared. A special mention to Saket Suman, whose exceptional effort played a crucial role in connecting us with Alex Lamb (Microsoft Researcher). We are immensely grateful for the bridge he built, allowing us to tap into Alex’s expertise. We express our heartfelt thanks to Alex Lamb from Microsoft, who graciously shared insights from his experiences with a similar project. His willingness to spare time from his busy schedule to guide us through the nuances of the process has been a defining factor in our success. A special acknowledgment to Professor Rachel Brown for her invaluable contributions. Taking the time to advise us on our spatial problem and lending her expertise to tackle the reading order challenge with Japanese texts. Finally, a special thanks to our peers, who’s pertinent questions, constructive discussions, and unwavering encouragement have created an atmosphere of collaboration and shared growth.
Course
Data Science 210. Capstone , Fall 2023More Information

