


")
")


")


ViTAL: A Smart Sentence Completion Tool for Chest X-Ray Reporting
ViTAL is an AI-powered sentence completion tool for chest X-ray reporting
Problem & Motivation
Radiologists in the U.S. perform on average over 70 million chest X-rays each year. Furthermore, the cost for imaging and professional reading/interpretation is between $150 and $1,200. While being expensive, the turnover time for medical radiologist reporting at major hospitals takes on average 245 to 288 minutes. However, increasing the speed radiologist reading is shown to have a significant impact on the accuracy of the report without tooling improvement. It is reported that the error rate of major misses increased was 26% among the radiologists reporting at a faster speed, compared with 10% at normal speed.
Solution
In this project, we developed a chest X-ray annotataion tool, Vision and Text Informed Autocomplete Language (ViTAL) model, that provides sentence completion suggestions based on the specific X-ray that is being analyzed. We also provide a dynamic saliency map that highlights which part of the X-ray the model is ‘looking at’ when providing the autocomplete suggestions.

Data Sources
To enable image captioning capability in our model, we pretrain it on the MS COCO dataset which is a large-scale object detection, segmentation, and captioning dataset containing over 330k images with more than 200k labels.
We then fine-tune ViTAL using the MIMIC-CXR database. It contains 377,110 chest X-ray images corresponding to radiographic studies performed at the Beth Israel Deaconess Medical Center in Boston, MA. The dataset also includes radiology reports from clinicians trained in interpreting imaging studies, summarizing their findings in a free-text format. For the scope of this project, we filter to keep only Posterior Anterior (PA) X-rays. This reduces the dataset size to 81K train images and 1.3K test images.
As previously mentioned, the MIMIC-CXR data is collected from a single hospital in Boston, MA. Therefore, the diversity of the data is limited to the demographics of the area surrounding the hospital. Additionally, the data is deidentified and does not allow for statistical analysis of the demography. As a result, we limit the claims made in this project to these constraints in consideration.
Model
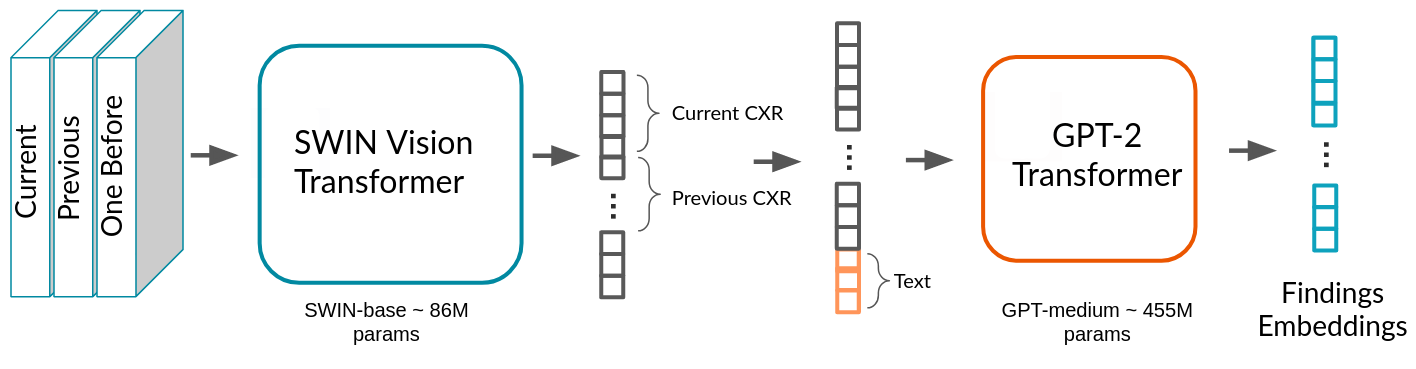
The ViTAL model consists of two parts: a vision encoder model and a language decoder model, as shown in the diagram below. Swin Transformer is used by ViTAL to convert X-ray images into embeddings. Any text provided as context is concatenated with the image and its output hidden states. The text tokens are then converted into embeddings using the input embedding layer of the GPT-2 model. The concatenated hidden states of the vision and the text form the input to the GPT-2 model. Finally, GPT-2 outputs finding embeddings which are decoded to generate radiologist medical report findings. This enables the autocomplete feature of ViTAL as user types the report.
Real World Impact
As we continue to improve this tool’s capability and its accuracy, we anticipate that most X-ray reports will be completed by radiologists simply accepting suggestions by quickly referencing the salient map locations. This would accelerate report generation without compromising reporting precision. With this reduced turnaround time, patients requiring urgent care can benefit from faster diagnosis and earlier treatment. Additionally, we expect the cost of X-rays to decrease with the improved bandwidth of X-ray reporting.
Acknowledgements
We would like to express our sincere gratitude to our instructors Dr. Fred Nugen and Dr. Alberto Todeschini for their invaluable mentorship throughout this project. Their candid feedback and expertise guided us to a successful project. A big thank you to Dr. Joe Schwab for his advice on potential data bias and ethics. Last but not the least, we want to give a shout-out to our peers in Section 9, thank you for your feedback through the weeks. We are excited to show everyone our final product.
Course
Data Science 210. Capstone , Summer 2023More Information
")

Video
If you require video captions for accessibility and this video does not have captions, click here to request video captioning.