

")







AceInterview
Problem & Motivation
Picture yourself after leaving an interview, replaying every answer in your head, wondering: “Did I really bomb that question about what makes me a great leader?” This nerve-wracking ritual plays out daily for job seekers across the globe. In today's competitive job market, candidates spend hours on end preparing for interviews, yet often lack the comprehensive feedback needed to truly improve their performance. Current AI interview tools promise convenience but often deliver surface-level and generic feedback that fails to capture the nuances of successful responses. As a result, candidates are left in the dark about critical factors such as body language, tone, and authenticity—key elements that can be the deciding factors between securing a job or missing out.
AceInterview fills the gap in accessible interview coaching by providing a platform that transforms practice sessions into detailed learning experiences. Our interview analysis platform combines computer vision, audio signal processing, and AI to analyze all aspects of user performance - from facial expressions and body language to the clarity of responses and overall engagement. Users receive actionable and comprehensive feedback on key behaviors and soft skills, along with specific recommendations for improvement. Our mission is to create an accessible project to help job seekers secure their dream jobs.
Data Source
The dataset used for this project came from Dr. Ehsan Hoque of the University of Rochester (formerly MIT), who collected this data for his study regarding interview performance and metrics. The dataset consisted of 138 videos of interviews (ranging from 2 to 15 minutes long) along with 9 Mechanical Turk scores per interviewee on 18 different metrics regarding interview performance. These metrics were rated on a 7-point Likert scale and ranged from things like “Awkward” and “EngagingTone” to “RecommendHiring” and “Overall”.
Data Science Approach
We performed exploratory data analysis and literature review to determine which metrics were most likely to be predictive of the “RecommendHiring” feature. Our findings led us to build visual, verbal, and emotional extractors for some of these key features. These features include a smile detector, off-center gaze detection, posture detection, face-touching detection, prosody extraction (jitter, shimmer, and intensity), word & filler word transcription, and emotional features derived from facial and vocal expressions.
For smile detection, we used a Haar Cascade model to detect faces in videos and then fed this portion of the frame into another Haar Cascade model. A pre-trained convolutional neural network was utilized for gaze detection. MediaPipe models were implemented to identify key body landmarks, such as eyes and shoulders, which were then used to estimate user posture and face-touching detection. Prosody extraction was performed using the Parselmouth library to estimate the user’s spoken tone. Filler words were detected and transcribed with CrisperWhisper. Lastly, emotional features from facial and vocal expressions were gathered from Hume.
Overall, our solution aggregated the outputs of 7 feature extractors into a prompt, sent to a Large Language Model (Gemini) to produce feedback for the user. To evaluate these results, the generated feedback was sent to an LLM as a judge to determine its utility and iteratively improve model performance.
To evaluate the performance of our solution, the aforementioned LLM as a judge assigned scores on a 7-point Likert scale for the feedback’s actionability, clarity, constructiveness, specificity, and depth of insight. Improving these metrics was our primary goal to provide the best feedback to our users. Our solution was tested on all 138 videos to see how much we could improve this metric.
Evaluation
Grounding
Detecting hallucinations is an unsolved problem in the generative AI space. While Retrieval Augmented Generation approaches can help, which inspire our feature extractors, there is currently no way to ensure an absence of hallucinations. Our team has sampled feedback from our generative model and spot-checked references the model alludes to regarding specific actions or words in the videos and their associated timestamps. So far we have not encountered egregious instances of hallucinations.
Large Language Model as a Judge
Lacking human labels is a problem often faced by researchers. Our project is no different. We have focused on generating feedback, but due to time and resource constraints have not been able to acquire human ratings to evaluate the generated feedback. To save time and resources, we opted to use an LLM as a judge. Zheng et al. 2023 (https://arxiv.org/pdf/2306.05685) showed that LLM judges can be highly correlated with human judgments. This is aided by the human feedback reinforcement learning scheme used to train these LLMs to align these models with human preferences. As such, we attempted to build our own automated LLM as a judge system. Our initial iteration also uses Gemini as the model Judge. We had our LLM judge on 5 categories:
- Actionability: how actionable the feedback is based on the specificity and clarity of the recommendations provided
- Clarity: how clearly and logically the feedback is presented
- Constructiveness: how constructive and motivational the feedback is.
- Specificity: how specific and detailed the feedback is.
- Depth of Insight: the depth of analysis in the feedback.
These were rated on a 7-point Likert scale similar to those found in psychological studies where 1 indicates a poor score and 7 indicates an excellent score. We selected a couple of feedback sample pairs for comparison and generally found that our own preferences were directionally captured by the LLM judge.
Results
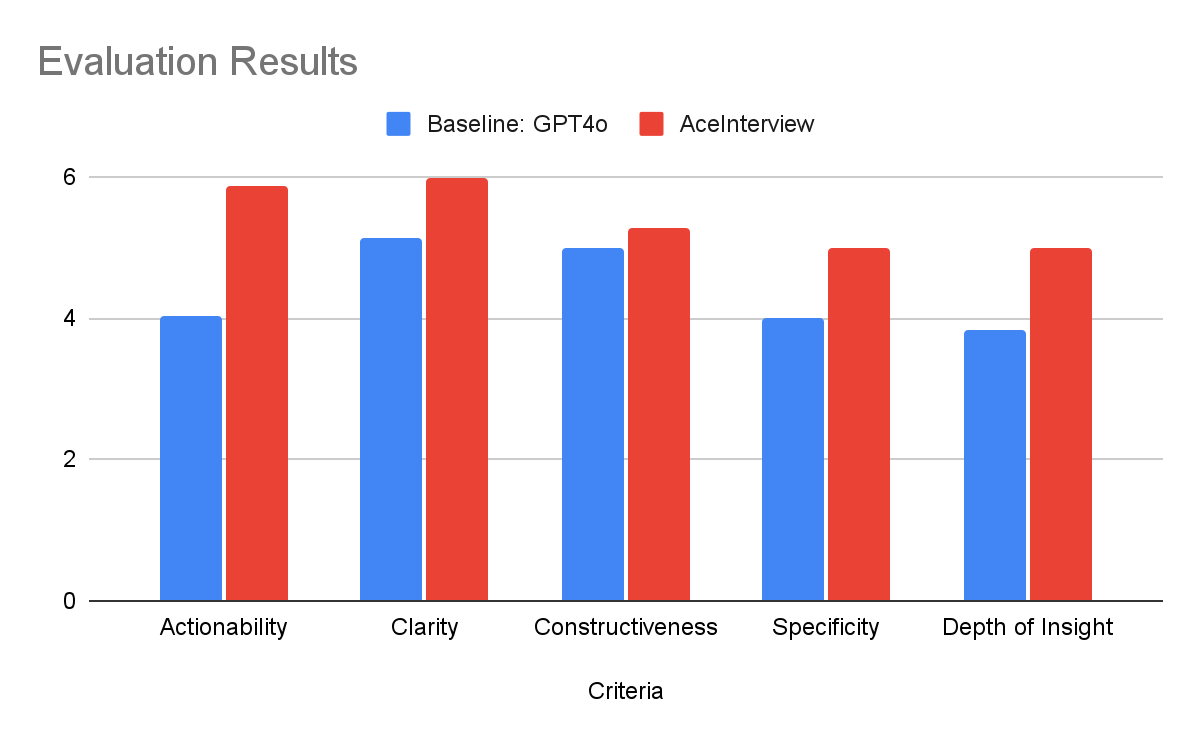
We run our baseline feedback and our current solution feedback through the LLM as a Judge and extract the scores. Our current solution scores better on all categories relative to our GPT-4o baseline with the most gain in actionability with a gain of almost 2 full points. There is only a slight increase in the Constructiveness attribute across our models. Overall, these results show that our approach is promising but requires further validation by human evaluators and in practice by users.
Key Learnings and Impact
The main challenge of this project was creating generalizable features and combining each extracted output to generate comprehensive feedback. For example, the dataset used for training and evaluation had a different camera angle than typical online interviews, and our group needed to ensure that our visual feature extractions must apply to various camera angles, zoom, and subject placements. By allowing for generalizability, the intended impact of this project is to create an accessible, easy-to-use platform that can generate personalized interview behavior feedback for all users.
Acknowledgments
We would like to thank Professor Ehsan Hoque, the University of Rochester, and the Massachusetts Institute of Technology for providing the dataset we used in this project.
I. Naim, I. Tanveer, D. Gildea, M. E. Hoque, Automated Analysis and Prediction of Job Interview Performance, to appear in IEEE Transactions on Affective Computing.