

")






AgriMed: Mitigating Cropland Defects
Problem & Motivation
Agriculture is one of the largest sources of greenhouse gas emissions contributing to climate change. At the same time, increased frequency and severity of extreme weather events due to climate change are threatening the health and productivity of croplands. Precision agriculture is a solution that leverages multimodal data to empower farmers to optimize crop yields, while reducing use of greenhouse gas emitters like fertilizer. Despite its potential, as of 2023, only 27% of U.S. farms have adopted precision agriculture, primarly due to high up-front and maintenance costs and data ownership concerns. In the US, small family farms make up the majority of farms but a minority of the profits earned. Small-scale farmers struggle most to afford technologies that can improve their crop yields and, ultimately, their profit. By making precision agriculture affordable and accessible, AgriMed can enhance these farms’ productivity and promote sustainable farming practices.
Our Solution
AgriMed is a precision agriculture tool that empowers small-scale farmers to optimize crop yields and reduce use of harmful pesticides, all for a fraction of the cost of existing tools. AgriMed is a two-in-one solution, consisting of AgriMap and AgriBot. AgriMap takes in multispectral aerial cropland imagery and maps the incidence of common crop attributes such as nutrient deficiencies and weed clusters. Users can then consult AgriBot, an agriculture-specialized chatbot, to develop targeted mitigation strategies for these defects and generate other recommendations for managing their farms. AgriMed is a one-stop solution to make precision agriculture accessible to small-scale farmers.
Data Source & Data Science Approach
AgriMap
Data Source
AgriMap is a semantic segmentation model trained on approximately 57,000 labeled images from the Agriculture-Vision Database, a high-quality and open-source multi-spectral aerial image dataset. The dataset contains expert-labeled RGB and NIR images of corn and soybean cropland in Iowa and Illinois. All images are uniform in resolution of 512x512 pixels. In addition to RGB and NIR images, the dataset is structured to contain binary label masks for each class, a mask indicating the boundary of the field, and a mask indicating invalid pixels in the input image. While the original dataset includes 9 attribute labels, ‘storm damage’ images were removed due to the small sample size, leaving 8 remaining attributes:
- Drydown: Natural drying process of grains prior to harvest.
- Nutrient Deficiency: A lack of essential nutrients for growth.
- Weed Cluster: A patch of weeds.
- Double Plant: Sowing of multiple seeds in the same crop row.
- End Row: Crop rows planted at a field's edge.
- Waterway: A channel that directs the flow of excess water; runoff or irrigation.
- Planter Skip: Lack of seed deposits in a crop row.
- Water: Excess standing water on a field due to heavy rainfall and poor drainage.
Data Pre-Processing
We performed the following steps to simplify the modeling task and prepare the data for training:
- Removed images with overlapping attributes (1830 images).
- Removed images containing invalid pixels (495 images).
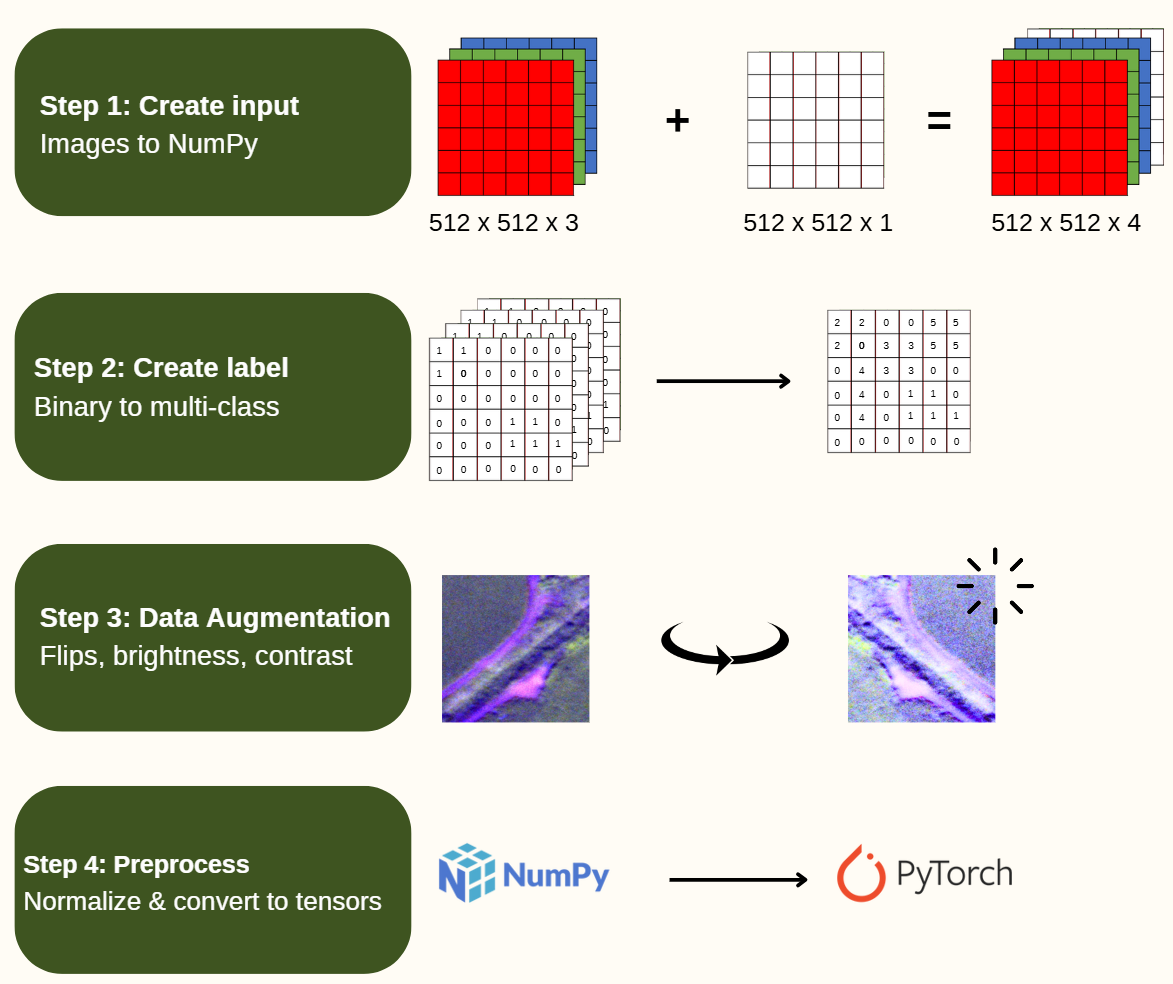
- Created the model input:
- Converted images to NumPy arrays.
- Combined the RGB & NIR channels into a 4-dimensional array.
- Created the ground truth label:
- Combined the binary label masks into a single, multi-class label mask where each pixel in the image is represented by a number corresponding to an attribute.
- Performed data augmentation:
- Applied random flips and adjusted the brightness and contrast of the images to improve generalizability of the model.
- Pre-processed the data per the model specifications:
- Applied rescaling and normalization to align with the model input requirements.
- Converted the NumPy arrays into Tensors.
Model Overview
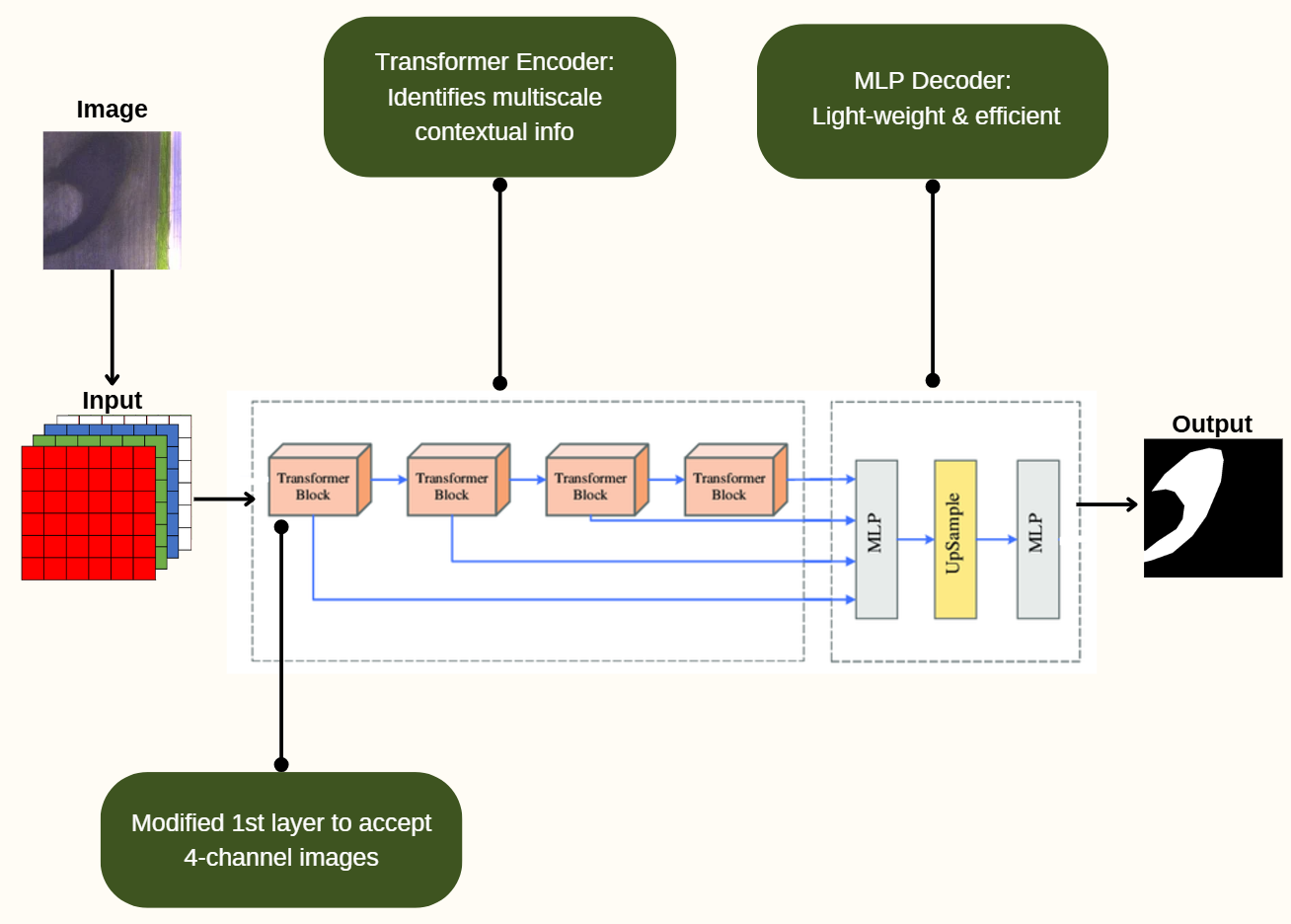
The computer vision technique selected for AgriMap is semantic segmentation, a computer vision task whereby each individual pixel is classified. This approach is most appropriate for delineating between boundaries and assigns labels to all pixels of the input image.
AgriMap builds upon the SegFormer model, a semantic segmentation model introduced by Nvidia. The model architecture contains a transformer encoder and MLP decoder, a novel architecture that set new state-of-the-art in efficiency, accuracy and robustness across three publicly available semantic segmentation datasets. Specifically, AgriMap fine-tunes SegFormer-b5, the largest pre-trained model available containing 82M parameters, with a modified first layer that accepts 4-channel (RGB+NIR) images instead of 3-channel (RGB) images.
Model Training
During model training, one of the most significant drivers of model performance was the loss function. In this particular case, the goal of the loss function was to address two main problems: (1) account for significant class imbalance within the dataset and (2) optimize predictions based on the quality of overlap between the predicted label and the ground-truth label.
Based on existing literature and our experiments, we combined both class-weighted cross entropy loss and dice loss. Class-weighted cross entropy loss addresses class imbalance by applying a weight to each prediction based on the class. This ensures the model applies more focus to learning the classes represented in fewer training images. On the other hand, dice loss was created specifically for semantic segmentation tasks and optimizes based on the quality of the overlap between the predicted label and the ground-truth label. The combination of these metrics achieved the best performance during model training.

Model Evaluation
Model performance was measured using intersection over union (IOU) which, similar to dice loss, measures the quality of overlap between the predicted label and the ground-truth label. The IoU was calculated for each class individually and then averaged to produce the final evaluation metric: mean intersection over union (mIOU).

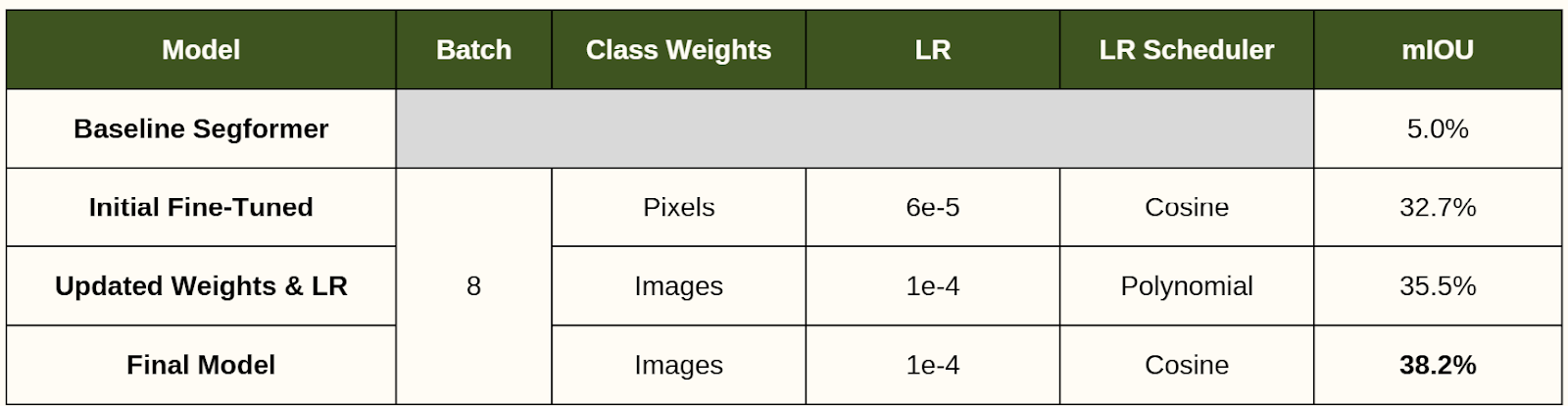
As a baseline, we ran our test dataset with the out-of-the-box SegFormer model. The baseline model performance was poor, achieving a 5.0% mIOU. This result was not unexpected as SegFormer was not pre-trained on any aerial imagery.
A review of existing literature indicated that a batch size of two was ideal for training SegFormer on the Agriculture-Vision dataset. However, due to resource constraints, our batch size was limited to eight. Based on this constraint, the main levers we had at our disposal to influence training performance were the class weights and learning rate. Class weights based on the inverse quantity of training images within the dataset and a higher learning rate to offset the higher batch size ultimately achieved the best performance. Our best performing model achieved a 38.2% mIOU on the test dataset.
User Journey & Deployment Architecture
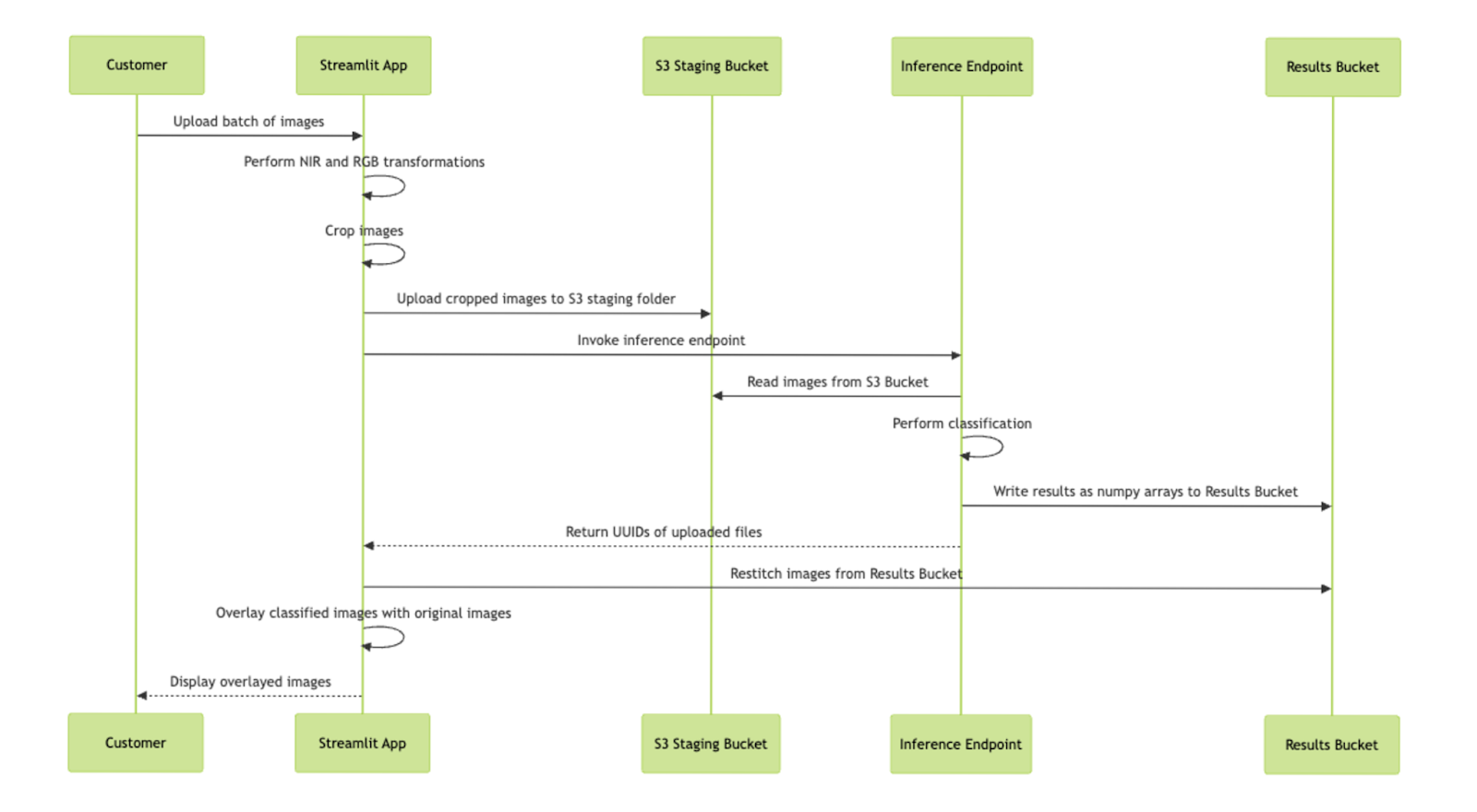
- The user uploads two images: an RGB-channel image and an NIR-channel image. Both images are uploaded to an AWS s3 bucket for future retrieval.
- The images are combined and cropped into uniform 512x512 pixel segments through our Streamlit application, then uploaded to the AWS s3 bucket.
- The Sagemaker endpoint is invoked to perform inference on all image segments using the fine-tuned SegFormer model to produce a class label at the pixel level. Results are formatted into numpy arrays and saved to the AWS s3 bucket.
- Our Streamlit application retrieves the results from the AWS s3 bucket and performs the following actions:
- Restitches the predictions into the original image size.
- Generates an overlay of the identified attributes on the original RGB-channel image provided and uploads this as an image in our AWS s3 bucket.
- Creates and uploads a dataframe of the various labels and pixel percentages.
- Generates statistics and visualizations surrounding SegFormer’s findings.
AgriBot
Modeling Approach
Our chatbot builds on an open source LLM, and we implemented it via LangChain in order to customize its functionality. We evaluated the following optimizations:
- Retrieval Augmented Generation (RAG)
- Conversational Memory
- Prompt Tuning
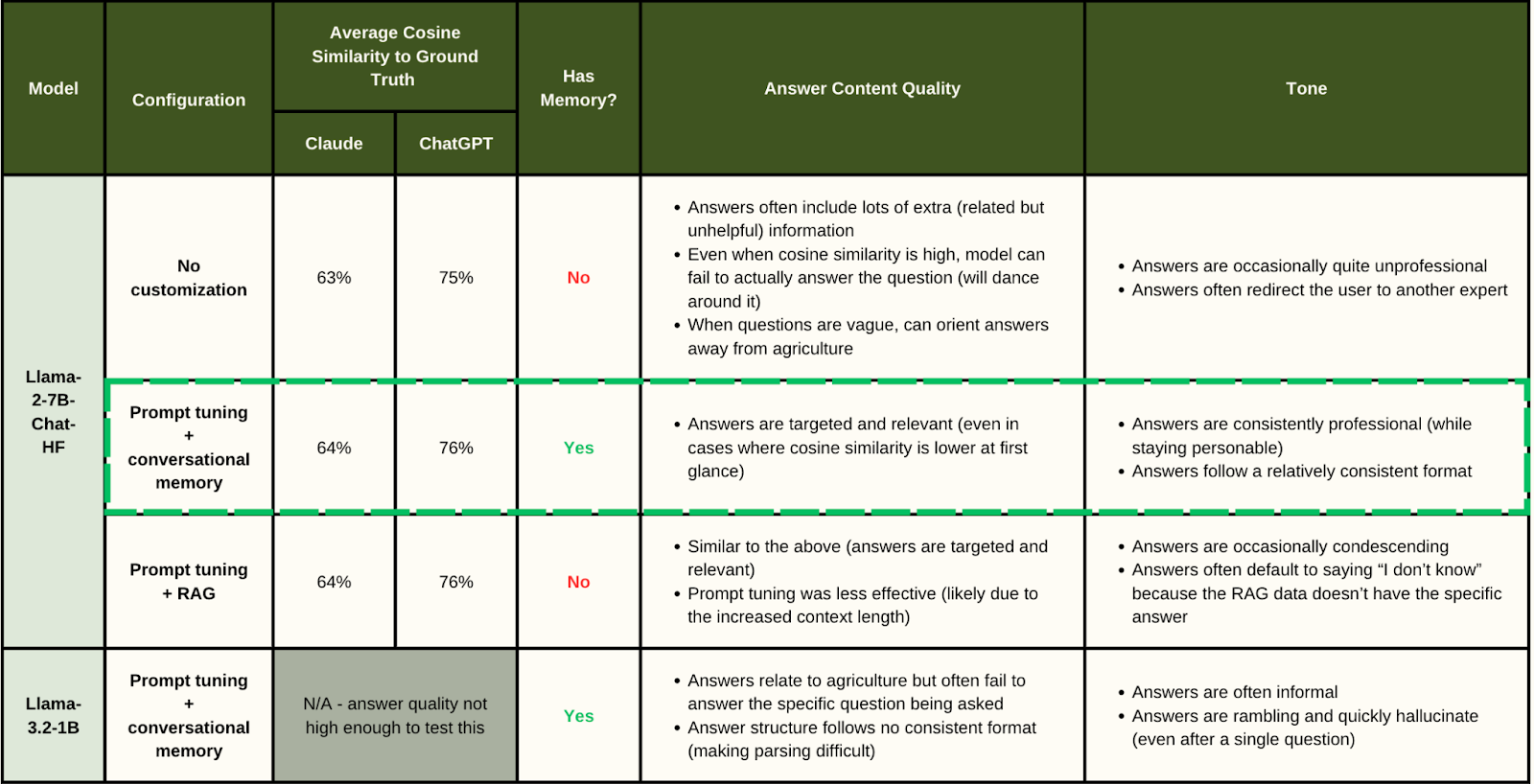
While building AgriBot, our key decision points were 1) which LLM to use as our base and 2) which optimizations from the above list to include in our final chatbot.
For point 1, we selected Llama and evaluated several configurations (specifically, Llama-2-7B-Chat-HF and Llama-3-1B.) Llama represents an ideal confluence of strong performance across various language tasks and efficiency with fewer resources compared to other large models. A key part of AgriMed’s value proposition is the combination of low cost and high performance, and we knew we wanted a powerful, open source model to build our chatbot.
For point 2, we implemented all three optimizations and evaluated them via an ablation study to determine the optimal combination.
RAG Data
We built our RAG dataset on Agri-LLM, a collection of ~9k snippets of processed text from multiple agriculture-related PDF documents. After data cleaning (stripping extra space and special characters, removing repetitive, table-like structures, and removing chunks below 150 characters) we were left with ~8.9k snippets. We searched the snippets for instances of India, the USA, China, and Brazil (the world’s top four agriculture producing countries) and noted that India was by far the most prevalent (at >2,500 mentions) with the US in second place (at ~500.) As AgriMed is targeted specifically at corn and soybean farmers in the midwest regions of the USA, this was not ideal. However, we proceeded with caution, as both corn and soybeans are grown in India.
Model Evaluation
We used a combination of existing state-of-the-art LLMs, judgment, and user testing to evaluate the performance of our chatbot and to select our ultimate model configuration.
Methodology:
- Used Claude to generate a list of 10 agricultural questions related to the agricultural components identified by AgriMap, then used both Claude and ChatGPT to generate ground truth answers to these questions.
- Verified the factual accuracy of the answers via Google research.
- Evaluated each of our proposed model configurations by asking them the list of questions, evaluating the cosine similarity of their answers with the ground truth, and judgmentally evaluating their answers for both content and tone.
- Additionally, asked a test user (a corn farmer in California) to ask AgriBot any questions they could think of. Our test user provided our team with feedback on accuracy, utility, and tone of AgriBot’s answers.
Findings:
Ultimately, we selected the Llama-2-7B model as our base and layered on prompt tuning and conversational memory. This model had the strongest cosine similarity to our ground truth answers (though this advantage was slight,) provided consistently targeted, relevant answers, and used a professional tone and consistent format throughout. User testing confirmed the accuracy of its answers.
Note that we may have achieved better performance with a larger instance of Llama. However, Llama-2-7B already pushed the limits of our deployment capabilities, so we did not evaluate any larger models.
User Journey and Deployment Architecture
- User → Streamlit: User inputs a prompt.
- Streamlit → FastAPI: Streamlit sends the prompt, via HTTPS, to our FastAPI code hosted on a SageMaker endpoint via a custom docker image.
- FastAPI: Internal code has the LLM model loaded and ready to reply to any questions using context gained from our domain information stored in a vector database (FAISS) locally.
- FastAPI → Streamlit: FastAPI’s HTTP Response is returned to the Streamlit app.
- Streamlit: Streamlit decodes and displays the response, maintaining conversational flow through session state and Streamlit Chat elements.
Key Learnings & Impact
Impact
- AgriMap: Identifies multiple common crop defects and attributes and is tailored to the top crops grown in the US.
- AgriBot: Streamlines farmer information search experience by giving just one concise, relevant answer per question.
- AgriMed Overall: One-stop shop for farmers remediating problems on their farms. o other applications on the market today combine this set of features.
Top Technical Challenges
- Handling the limitations of the agriculture-vision dataset such as class imbalance, low resolution of the training images, physical overlap and visual similarities between classes, and inability to access the original test dataset
- Expensive to train, even more expensive to deploy
- Customizing LangChain pipelines to add features, and then balancing those features with functionality
- Researching and implementing compatible AWS and Streamlit architecture
Future Work
- Incorporate unsupervised learning techniques to leverage larger unlabeled, raw cropland image dataset. We would utilize this supplemental data to improve learning of the CV model.
- Retrain the model with higher resolution training images (stitch together groups of original, lower resolution images). This would allow the model to better learn high-level contextual information from each training image.
- Obtain more RAG data - RAG may have been more effective with higher quality, more relevant data, but obtaining it was outside the scope of our project
Acknowledgements
We extend our gratitude to our project advisors, UC Berkeley W210 course instructors, and the organizations providing access to datasets. Special thanks to Chris Padwick at Blue River Technologies and Carlos Villalpando for their generosity in sharing their time and expertise with us.
References
Cap, Quan Huu. “The First Place Solution: Agriculture-Vision Prize Challenge 2024.” Aillis x IIPLab, 2024.
Chiu, Mang Tik, Xingqian Xu, Kai Wang, Jennifer Hobbs, Naira Hovakimyan, Thomas S. Huang, Honghui Shi, et al. 2020. “The 1st Agriculture-Vision Challenge: Methods and Results.” arXiv. https://doi.org/10.48550/arXiv.2004.09754.
Chiu, Mang Tik, Xingqian Xu, Yunchao Wei, Zilong Huang, Alexander Schwing, Robert Brunner, Hrant Khachatrian, et al. 2020. “Agriculture-Vision: A Large Aerial Image Database for Agricultural Pattern Analysis.” arXiv. https://doi.org/10.48550/arXiv.2001.01306.
“Family Farms.” 2017 Census of Agriculture, USDA NASS, 2021, www.nass.usda.gov/Publications/Highlights/2021/census-typology.pdf.
“Farming Drones for Crop Monitoring.” Agriculture Drones, 13 Mar. 2024, https://www.jouav.com/blog/agriculture-drone.html.
“Precision Agriculture: Benefits and Challenges for Technology Adoption and Use.” Precision Agriculture: Benefits and Challenges for Technology Adoption and Use | U.S. GAO, U.S.
Thisanke, Hans, Chamli Deshan, Kavindu Chamith, Sachith Seneviratne, Rajith Vidanaarachchi, and Damayanthi Herath. 2023. “Semantic Segmentation Using Vision Transformers: A Survey.” arXiv.https://doi.org/10.48550/arXiv.2305.03273.
Xie, Enze, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. 2021. “SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers.” arXiv. https://doi.org/10.48550/arXiv.2105.15203.