


")
")


")


AuthenText: Machine-Generated Text Detection in Student Essays
Problem & Motivation
In the new world of developing AI usage, industries are facing new and unique challenges. In the classroom setting, MGT (machine-generated text) usage in student essays presents new and complex challenges that educators must navigate. 1) Educators need to use additional time to not only evaluate student essays, now they have to check if these essays were written by a machine or by them. And this is a very complicated task for them to manually check, especially since we should not expect them to have a strong background in MGT. 2) Millions of students have been suspected of using MGT in their essays. 3) Current MGT detection tools are not as reliable as they claim. This is especially important, since false positives can lead to students being accused of using MGT, when they haven't.
Our capstone aim is to create an MGT detection tool that can determine if K-12 grade student essays are either MGT or human-written. Our ultimate aim is to uphold academic integrity and keep students accountable. Relieve educators the burden of manually checking every single essay for MGT and giving them back valuable time. And finally we aim to instill confidence to them regarding AI text detection tool's accuracy
Data Source & Data Science Approach
Our project used a dataset including 160000 student essays. This dataset includes a mix of human-written and MGT essays. The MGT is generated from various generative text models (e.g. ChatGPT, Llama-70b, Falcon 180b). We used a Binoculars score model to determine the distinction between MGT and human-written. It works by computing scores for the LLM tokens and evaluates the text based on how "surprising" the tokens are. The more "surprising" the text, the more likely it is to be human. This model was evaluated to be robust with an AUC of 0.9933.
Evaluation
Upon initial testing, we found that the model was robust at distinguishing between purely human-written essays and MGT essays with recall score of 0.98. We primarily looked at the recall score, since we wanted to prioritize minimizing false negatives. Since this result meant that students would get away with using MGT on their essay. Based on feedback from an educator, we learned that students can try evading MGT detection tools by replacing only parts of their essay with MGT, instead of solely relying on MGT. So our team generated new datasets by replacing (rephrasing or fill-in-blank) parts of human-written essays based on set percentages of masking tokens with MGT to evaluate the binoculars score model. This is to replicate the real-world scenario of a student replacing parts of their essay with MGT.
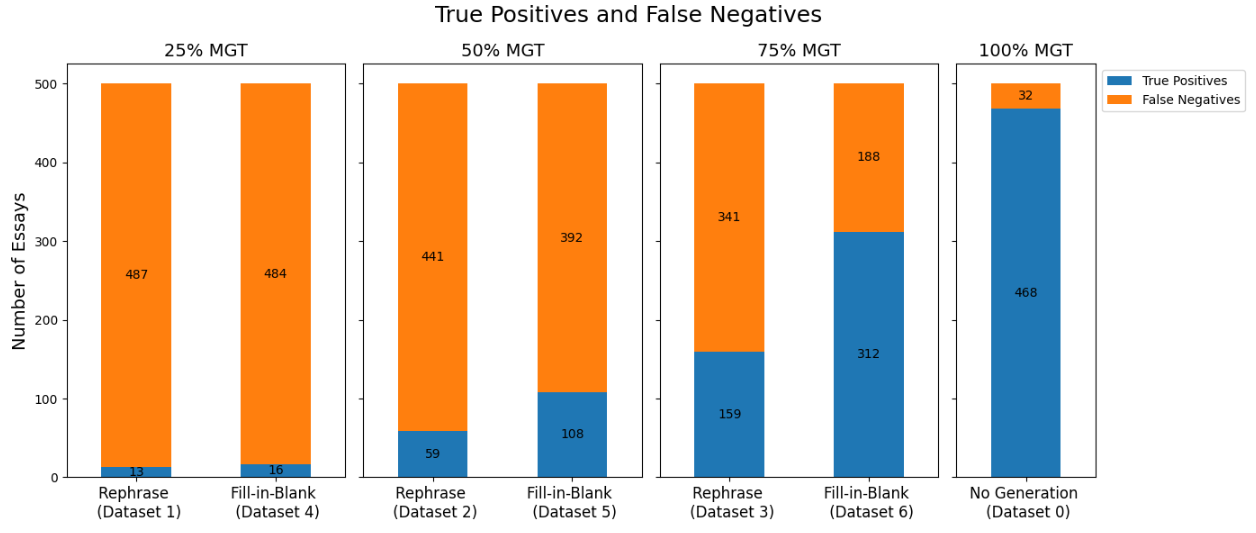
Key Learnings & Impact
While the model is robust at distinguishing between purely human-written essays and MGT essays, it falls short at determining partially MGT essays. We found that the more MGT present in a student essay, the better the model performed. binoculars is able to detect "Fill-in-blank" MGT more accurately than "Rephrase" MGT. To binoculars, there is more similarity between a completely human-written essay and an essay with a small amount of human text.
Acknowledgements
We want to give a major shoutout to Puya Vahabi and Kira Wetzel and our domain expert. Their feedback has been extremely helpful, and we cannot thank them enough.
Course
Data Science 210. Capstone , Summer 2024More Information


Video
If you require video captions for accessibility and this video does not have captions, click here to request video captioning.