

")







AllerGenie
Turn food fear into food freedom one meal at a time, with an allergen-detection and multimodal recipe-generation app.
Problem & Motivation
Food allergies are a growing public health concern, with approximately 33 million Americans having an allergy. People with food allergies must carefully explore food options by checking ingredients, reading detailed labels, and searching online for allergen-free recipes. AllerGenie, an allergen-detection and recipe-generation app, is our solution to help people with allergies purchase confidently and inspire cooking.
Our goal is to turn food fear into food freedom.
Data Source and Data Science Impact
AllerGenie is your one-stop shop for allergen detection and recipe generation!
Our allergy detection feature is supported by OpenFoodFacts, a comprehensive food products database, that we parse through to support you in making better food choices. All you need to do is scan your food product and we’ll cross-check our database to make sure it fits your dietary needs.
Our recipe generation feature carefully considers your dietary restrictions and cuisine cravings to generate three recipes that are right for you. Using a fine-tuned Llama3 8b model, we’re able to create a Retrieval Augmented Generation (RAG) pipeline that returns three delicious and safe recipes to users. The recipes are complemented with an AI-generated image of each dish.
Data Pipeline
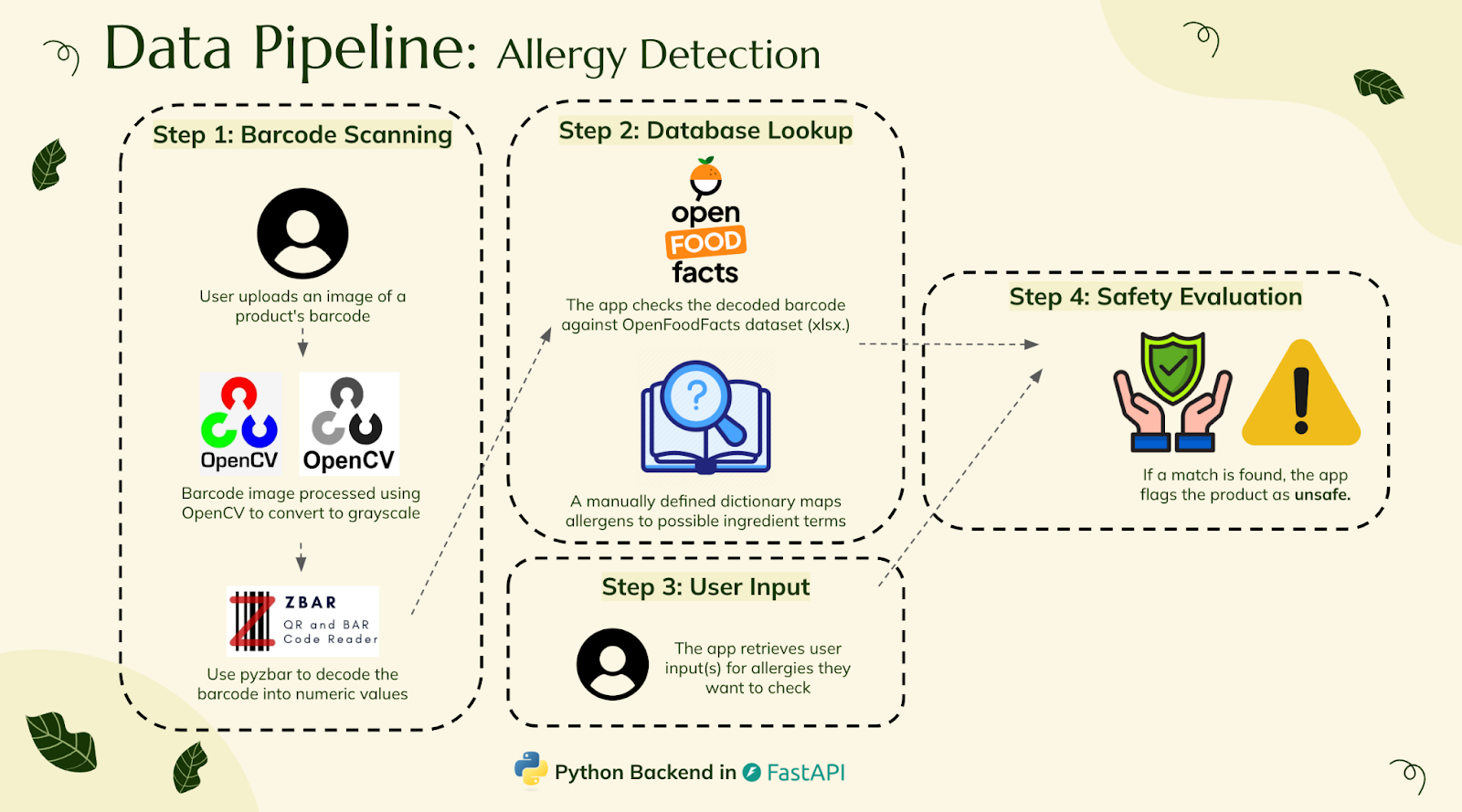
Step 1: Barcode Scanning
- Users upload a product barcode image
- OpenCV processes the image to grayscale
- Pyzbar decodes the barcode into numeric values
Step 2: Database Lookup
- The decoded barcode is matched against the OpenFoodFacts product dataset
- A custom dictionary maps allergens to ingredient terms for cross-referencing
Step 3: User Input
- Users input specific allergens they want to avoid
Step 4: Safety Evaluation
- The app checks if any ingredients match user-provided allergens
- If a match is found, the product is flagged as unsafe
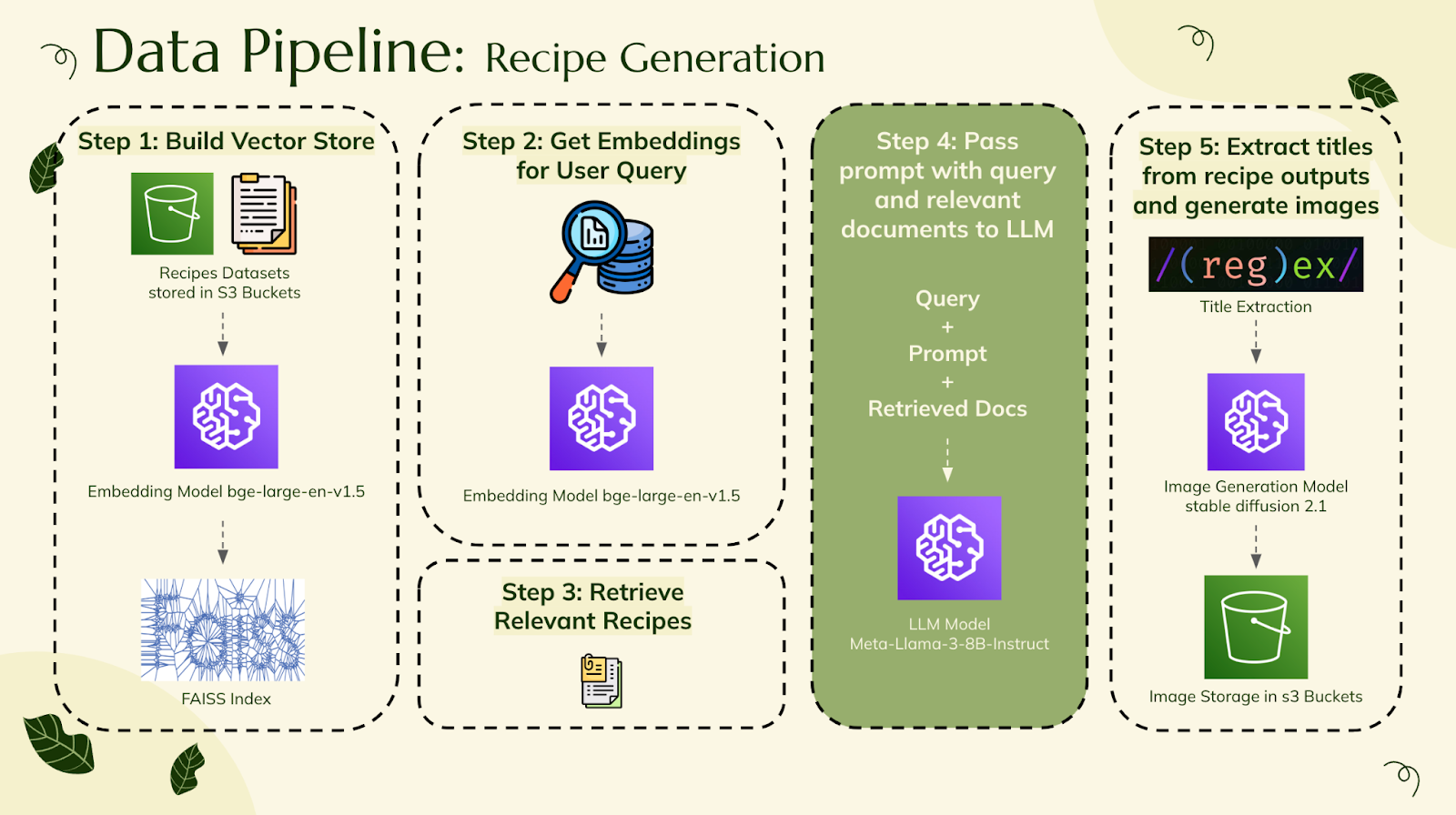
Step 1: Build Vector Store
- Recipes datasets are stored in S3 buckets
- The embedding model (bge-large-en-v1.5) converts recipe data into vector representations
- FAISS (Facebook AI Similarity Search) index is created to efficiently store and retrieve vector embeddings
Step 2: Get Embeddings for User Input
- User inputs are processed to generate vector embeddings using the same embedding model (bge-large-en-v1.5)
Step 3: Retrieve Relevant Recipes
- The FAISS index retrieves the closest matching recipes based on the user's vector embedding
Step 4: Pass Query to LLM
- The user's query, a prompt template, and the retrieved recipe documents are passed to an LLM (Meta-Llama-3-8B-Instruct) to generate recipe suggestions
Step 5: Extract Titles and Generate Images
- Extract recipe titles using regex functions
- Generate recipe images using an image generation model (stable diffusion 2.1)
- Store generated images in S3 buckets for frontend retrieval
Both applications are hosted on FastAPI with a Flutter-based frontend. The recipe generation feature leverages a RAG pipeline powered by AWS SageMaker endpoints for an embedding model and a large language model to deliver personalized recipe suggestions. The allergen detection feature primarily utilizes Python with libraries like OpenCV and Pyzbar for barcode processing, combined with a robust product database for safety evaluation.
Model Evaluation: Large Language Model Metrics
In developing AllerGenie, we evaluated three different Large Language Models (LLM), Mistral 7B, Mistral 7B-Instruct and Llama-3-8B-Instruct, using different prompt and parameter combinations.
Our four evaluation criteria were as follows:
- BLEU Score (20% weighting): Measuring precision, BLEU calculates how much our text overlaps with our reference gold answer text. BLEU assigns a score on a scale of 0 to 1, with 1 being the “perfect” score.
- ROUGE Score (20% weighting): Measuring recall, ROUGE assesses how much content from a gold answer (otherwise known as a ground truth answer) is included in the reference text. ROUGE assigns a score on a scale of 0 to 1, with 1 being the “perfect” score.
- Readability Score (20% weighting): To ensure our product was appropriate for most ages and education levels, we included a “Readability Score” as represented by the Flesch score. The Flesch score assigns text a rating from 0 to 121, with 0 being very difficult to read and 121 being very easy to read. For our purpose, we divided the Flesch score by the highest score, 121, to scale our scores to 0 to 1.
- Allergen Exclusion Score (40% weighting): Allergen exclusion was the most important metric in our analysis. The Allergen Exclusion Score (AES) is defined by the presence or lack thereof of the user’s registered allergens in the final recipe, according to allergy lists provided by John Hopkins. Scores of 1 indicate that the model correctly generated a recipe without using any of the user’s allergies, whereas recipes containing one allergen were given a score of 0.5, and recipes with even more allergens were given a higher penalty (AES = 1 / 1 + # of allergens included).
To ensure the models were rigorously tested, for each model and prompt combination we generated five different recipes for a variety of cuisines and allergy scenarios (e.g. a brownie without eggs, or dumplings without shellfish). Each of these scenarios were scored using the criteria described above, and then averaged over the five scenarios.
Review the results of our testing:
- BLEU Score: Across the 3 different LLMs, Llama 3 8b outperformed the other two models with a Bleu Score of .40.
- Rouge Score: Across the 3 different LLMs, Llama 3 8b outperformed the other two models with a Rouge Score of .55.
- Readability Score: Mistral 7B performed best with a score of .62, however, allergens were more likely to be included in the recipe.
- Allergen Exclusion Score: Both Llama3 8b and Mistral 7B-Instruct v0.2 performed perfectly using optimized parameters, but Mistral 7B had some allergens slip through.
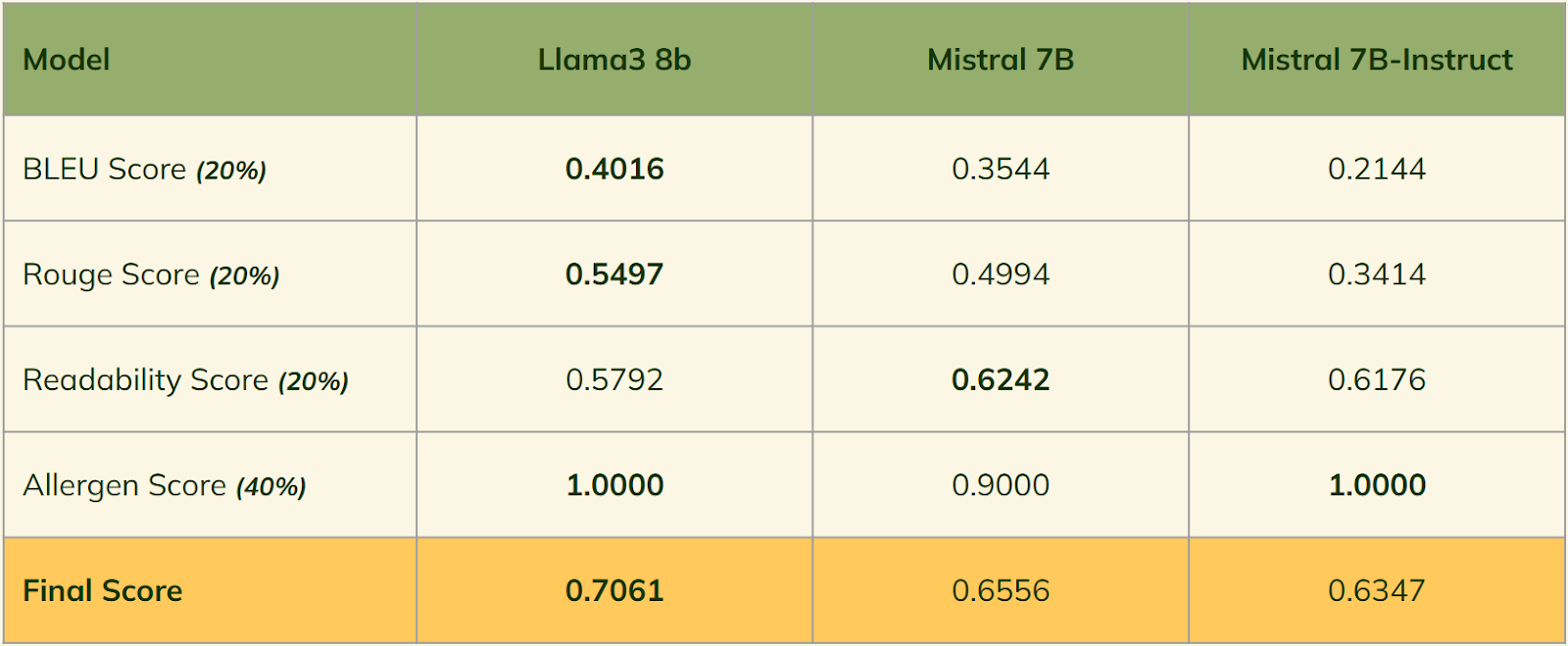
Overall, across the four different categories, Llama3 8b performed the best with a final weighted score of .71. Our runner-up was Mistral 7B with a weighted score of .66.
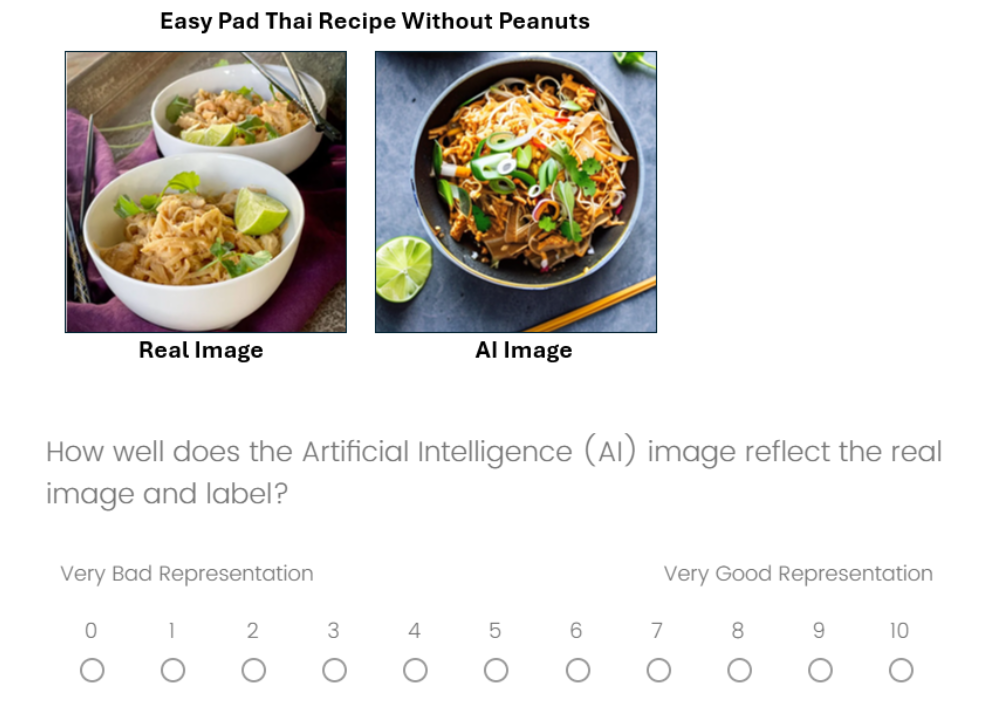
Model Evaluation: Generating AI Images
To evaluate AI images, we conducted a short five question survey to compare two different prompt types and two different image models. The survey was conducted online with 120 participants, where we asked each respondent to rate five AI food images on a scale of 0 to 10 (bad representation → good representation) against the real food image and recipe title. The AI images for each question were randomly assigned, creating a blind study. The highest performing model and prompt combination according to our analysis was the Stable Diffusion 2.1 Model with a short prompt, which had an average score of around 6 out of 10.
A key takeaway from our survey was that the model used was not statistically significant in predicting score, but using a shorter prompt was statistically significant at the 5% level.
Key Learnings and Impact
This semester was a great success for both AllerGenie's development and our personal learning. We learned:
- Despite being a world-class cloud computing service, AWS was not intuitive for first-time users. Throughout the term we learnt AWS’ different features such as EC2 Instance, Sagemaker, and S3 Buckets, but this was not without its challenges.
- We furthered our understanding of fine-tuning parameters when evaluating our LLM model output. For example, we learnt that for our use case the prompt was the most significant to get our recipes in the right format, whereas other variables like temperature played the most significant role in developing three unique recipes. Even for image models, it was important to test and consider different models and prompt combinations to improve performance.
- Developing a project is complex, and having a clear roadmap from the beginning helps. We don’t get to see the full development of a product in our day-to-day work, and experiencing every step in a “launch” gives us all greater appreciation for everyone's role, as well as the time requirement for each step: from idea inception, project management, model development/finetuning, budget management to front-end creation.
Where does this leave AllerGenie?
AllerGenie has a lot of growth potential. If the course was 10 weeks longer, we would incorporate more allergies into our website and also expand our app to different dietary preferences, such as vegetarian/vegan. Additionally, we would like to expand the capabilities of the barcode detection feature to be able to identify “raw” ingredients, such as an apple or a loaf of bread, that may not have a barcode. Lastly, and perhaps most importantly, we would work to improve the scalability of our model. Currently the recipe and image generation is rather slow and costly, so we would look for ways to improve the speed and cost of running the app.
Acknowledgments
Thank you to our Capstone Instructors, Kira Wetzel and Fred Nugen, for their invaluable advice and guidance and to the rest of our Capstone class who provided great feedback during the live sessions.
Course
Data Science 210. Capstone , Fall 2024