

")






HydroScale
Motivation
Data centers (DCs) are critical to modern infrastructure but are notorious for their resource consumption. American DCs collectively consume about 300,000 gallons of water per day, which is roughly equal to the water consumption of 100,000 homes (Eure 2024). In addition, more than 20% of these DCs withdraw water from medium to high stress watersheds (Privette, 2024).
The heavy reliance on water has led to growing tensions between operators and local communities. A notable example is Google's data center in The Dalles, Oregon, where a lawsuit demanding further transparency in water consumption revealed that Google had been consuming 29% of the town’s water (Rogoway, 2023). This revelation sparked opposition from local residents, who feared the depletion of critical water reserves. The conflict highlights the broader issue of water stress, which is becoming an increasingly urgent challenge due to droughts and changing precipitation patterns. Addressing these challenges requires rethinking water management practices to balance operational efficiency with sustainable resource use.
With increasing attention for AI, the global DC capacity demand is expected to see a compound annual growth rate (CAGR) of 22%, with the CAGR of generative AI workloads alone being 39% (Srivathsan et al., 2024). As a result, the water requirements for such systems are expected to strictly increase as well. While there has been a focus in addressing DC electricity consumption, much less investment and research has been done on the topic of DC water consumption.
How Data Centers Consume Water
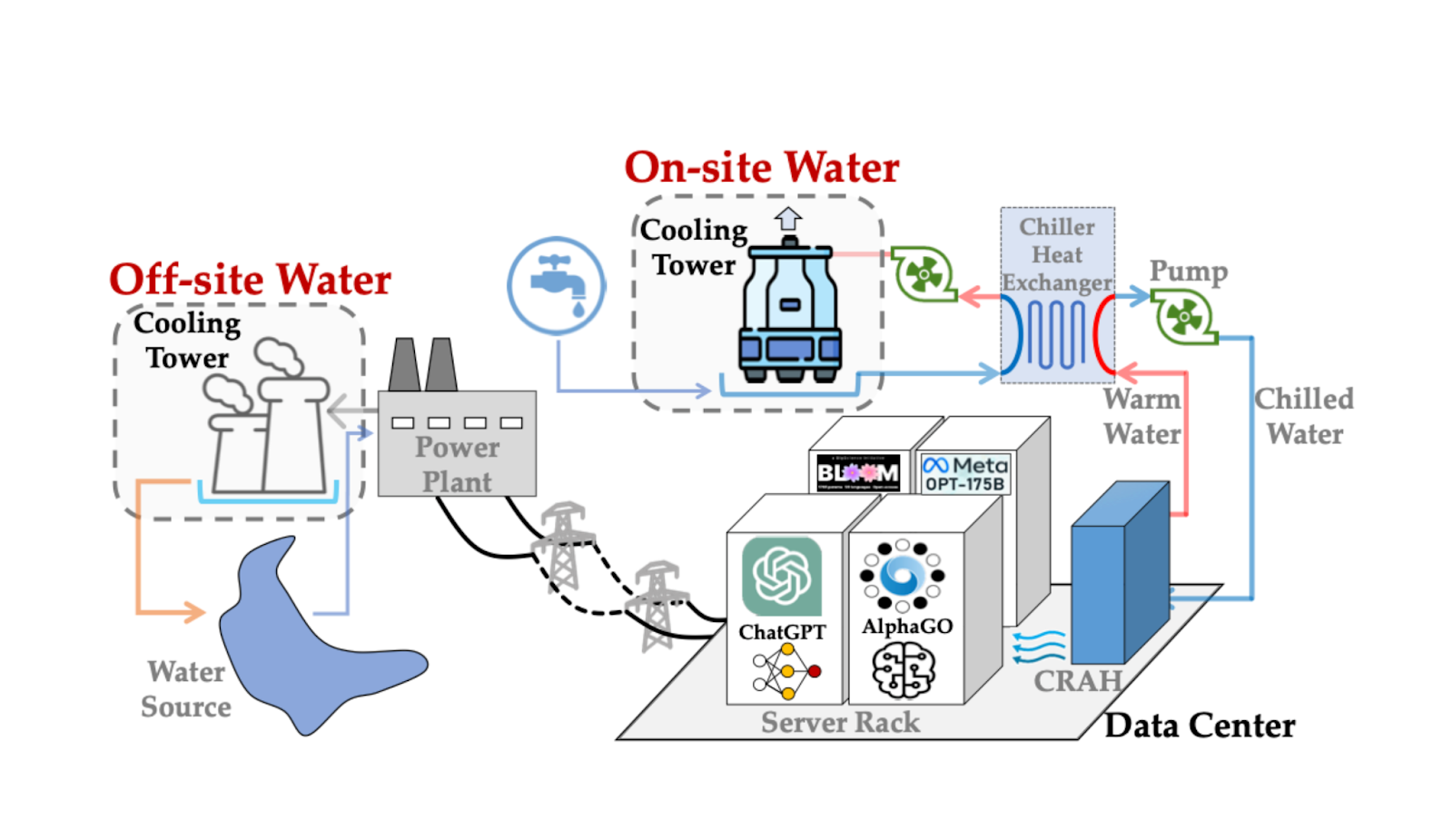
Two types of DC water consumption (Li et al., 2023)
The water behind data centers is used in two primary ways:
- Off-site water is involved in generating electricity to power the data center.
- On-site water is used directly in cooling systems within the data center.
Water efficiency of data centers is measured through Water Usage Effictiveness (WUE), which at a high level is the ratio of water consumption to IT equipment energy consumption. Despite the importance of WUE, there’s limited tooling available for predictive insights that can optimize water management. This project seeks to bridge that gap by providing 72-hour ahead forecasts for on-site and off-site WUE, empowering data center operators with visibility and actionable intelligence.
Our Solution
We developed HydroScale, a platform that provides granular, 72-hour ahead forecasts for WUE across the United States. Leveraging weather, energy, and operational data, HydroScale delivers both on-site forecasts tailored to individual data centers and off-site forecasts that consider broader regional factors. Our solution offers geospatial estimates of where water usage will be the most efficient, providing intelligence for tasks such as geographic load balancing. Additionally, DC operators may be interested in scheduling jobs at their own facilities in accordance with when the efficient times for off-site WUE will be. By equipping operators with these forecasts, we enable proactive decision-making to maximize water efficiency, optimize resource allocation, and enhance the sustainability of data center operations.
Data Overview and Pipeline
Due to the proprietary nature of data center operational data, as well as the insufficient transparency in tracking water usage, real-world WUE data is publicly unavailable. Thus, we simulate WUE according to the methodology outlined in A Dataset for Research on Water Sustainability by Pranjol Sen Gupta et al. with The University of Texas at Arlington. Off-site WUE is simulated based on data ingested from the US Environmental Protection Agency’s Emissions & Generation Resource Integrated Database (eGRID) and the Energy Information Administration’s Open Data API. On-site WUE is simulated based on weather data from the Iowa Environmental Mesonet.
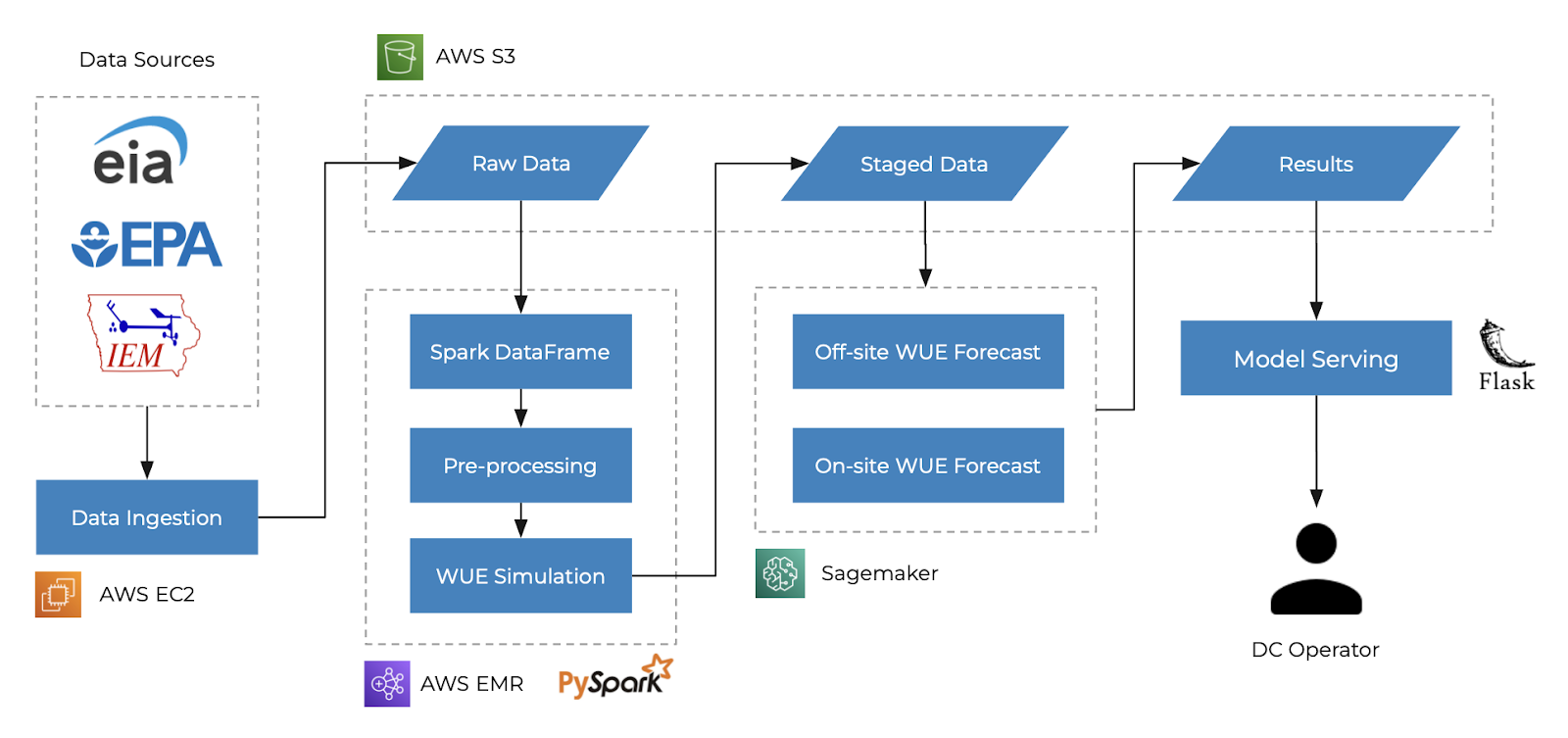
Complete Data Pipeline
The key steps in our data pipeline involve:
- Ingesting data from their respective data sources using an AWS EC2 instance.
- Leverage Elastic MapReduce to pre-process the data and perform the WUE simulations.
- Staging simulated data in an S3 bucket before being accessed in Sagemaker for developing off and on-site WUE forecasts.
- Serving forecast results to an end user through a flask web application.
While the initial dataset highlighted in A Dataset for Research on Water Sustainability contained 5 years of hourly data across 58 unique locations, we are interested in a finer granularity of on-site data that may be more representative of nation-wide WUE. Our final data contains 5 years of hourly off-site WUE across 19 unique eGRID regions and on-site WUE across 1153 unique locations.
Forecasting Methods
Off-site WUE Forecasting:
Our off-site models provide needed information for data center operators looking to decrease their water footprint by minimizing off-site water usage via energy generation, which accounts for ~75% of their water usage.
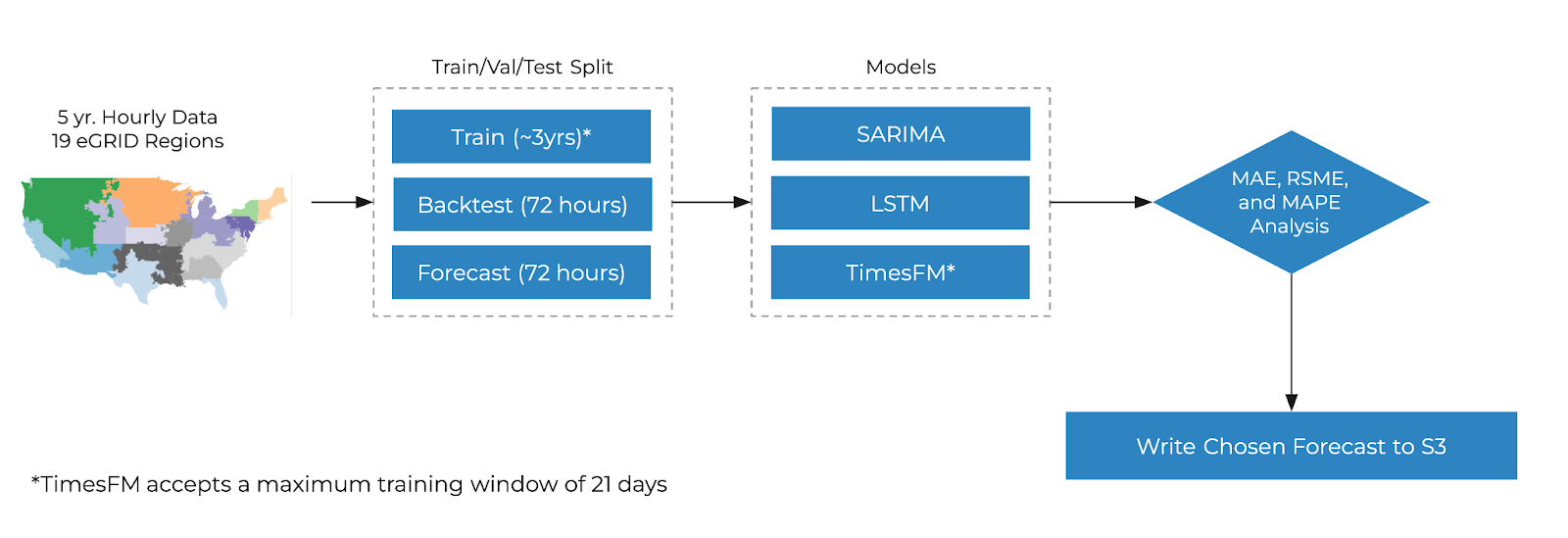
Off-site WUE Forecast Methods
We are equipped with hourly data for 19 geographically partitioned eGRID regions across the United States, where all cities in the same region share the same off-site water usage efficiency (WUE), which comes from indirect usage of water via electricity generation. We trained 19 models for each represented eGRID region in our off-site dataset. Every city that falls in the same eGRID region has the same off-site WUE prediction forecast, as they share similar embedded power source mixes (proportions of energy coming from sources like natural gas, nuclear, hydro, etc. that vary in terms of their embedded water usage). This reduces our problem space compared to the distributed and localized on-site WUE forecasts, which thereby allows us to compare and contrast more complex modelling methodologies (e.g LSTM, SARIMA, and TimesFM — Google's new foundation model for forecasting). After exploring an LSTM and a pre-trained model called TimesFM, we decided to use a classical forecast modeling method called SARIMA (seasonal autoregressive integrated moving average for our off-site data to predict future WUE because of its comparable performance to the other models as measured by RMSE, MAE, and MAPE metrics. This model takes advantage of seasonal patterns, which can improve the fit to training data and enhance prediction capability.
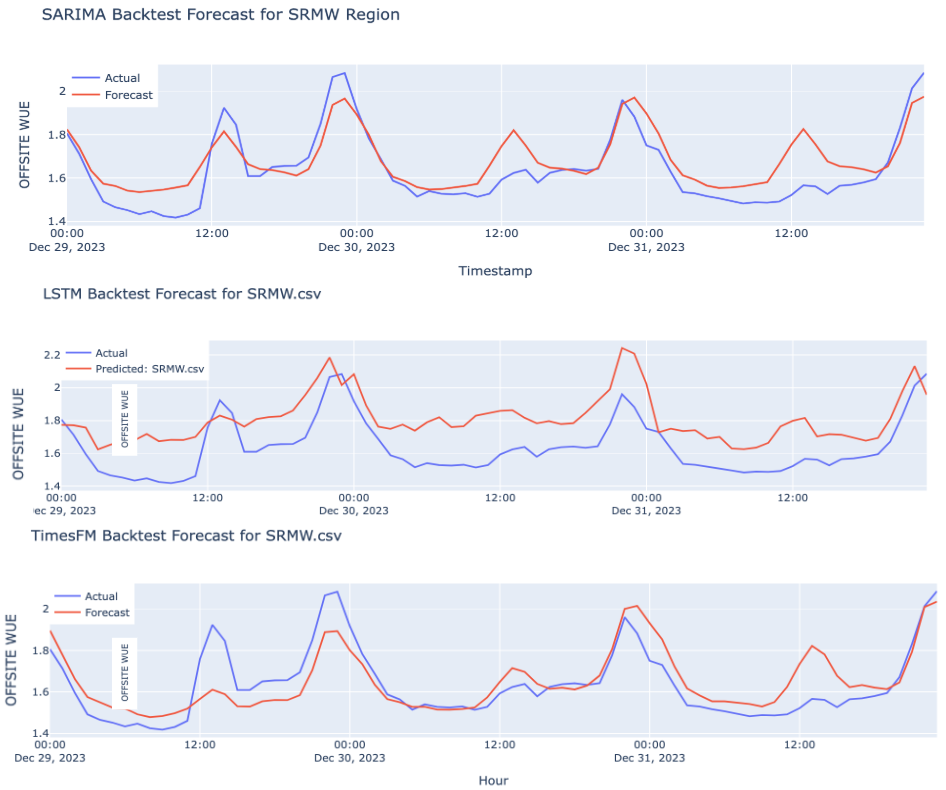
Off-site model comparison for SRMW eGRID region.
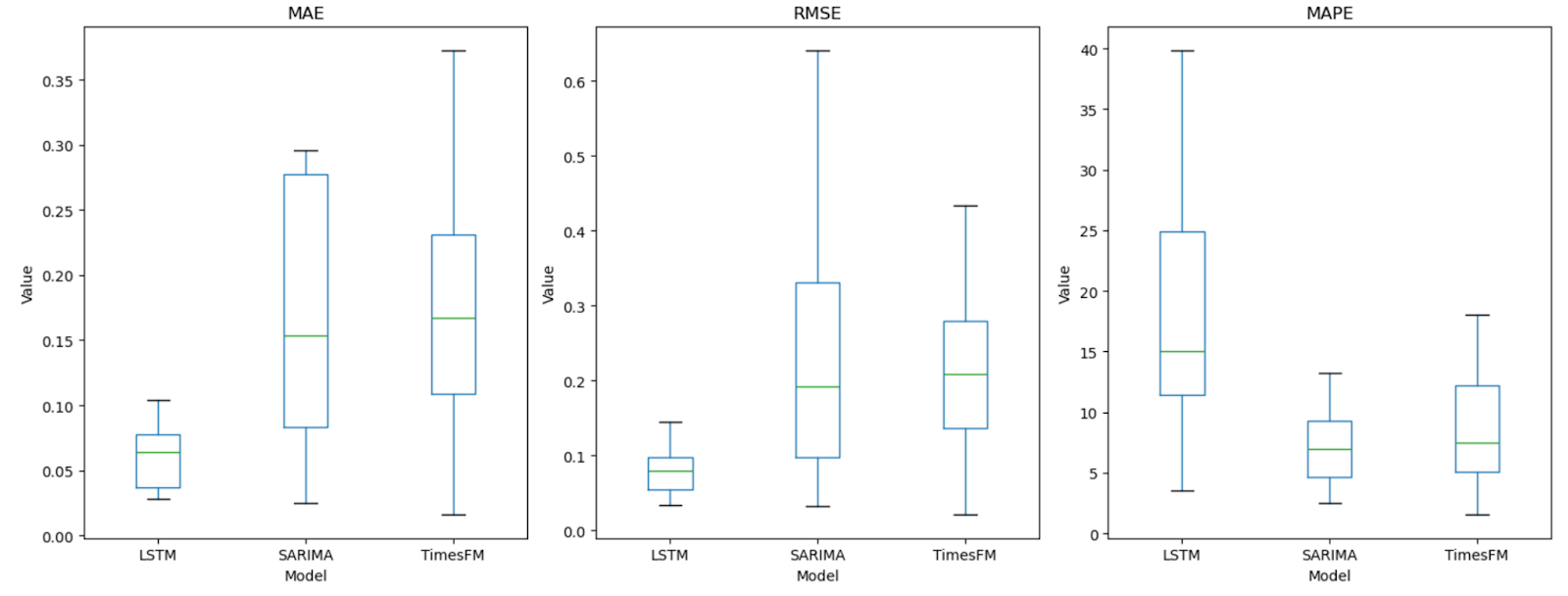
Off-site model comparison metrics across all models and all eGRID regions (57 unique models tested on a 72 hr backtest period).
We chose the SARIMA model as our optimal model that was the most robust across every geospatial pattern (as compared to the runner-up, the LSTM, which often failed to pick up seasonality signals and created flatlined forecasts for many of the eGRID locations).
On-site WUE Forecasting
On-site WUE is a metric that describes water usage efficiency of the water directly used at the data center for purposes like cooling IT hardware equipment. This metric depends on physical conditions: the type of cooling system used (e.g. evaporation cooling vs. water cooling) and the local weather, which impacts heat transfer and the amount of water needed to properly cool the data center. Our goal is to allow users to get an estimated picture of their on-site WUE (excluding data-center specific variables, such as cooling method, which operators can factor into the estimate themselves).
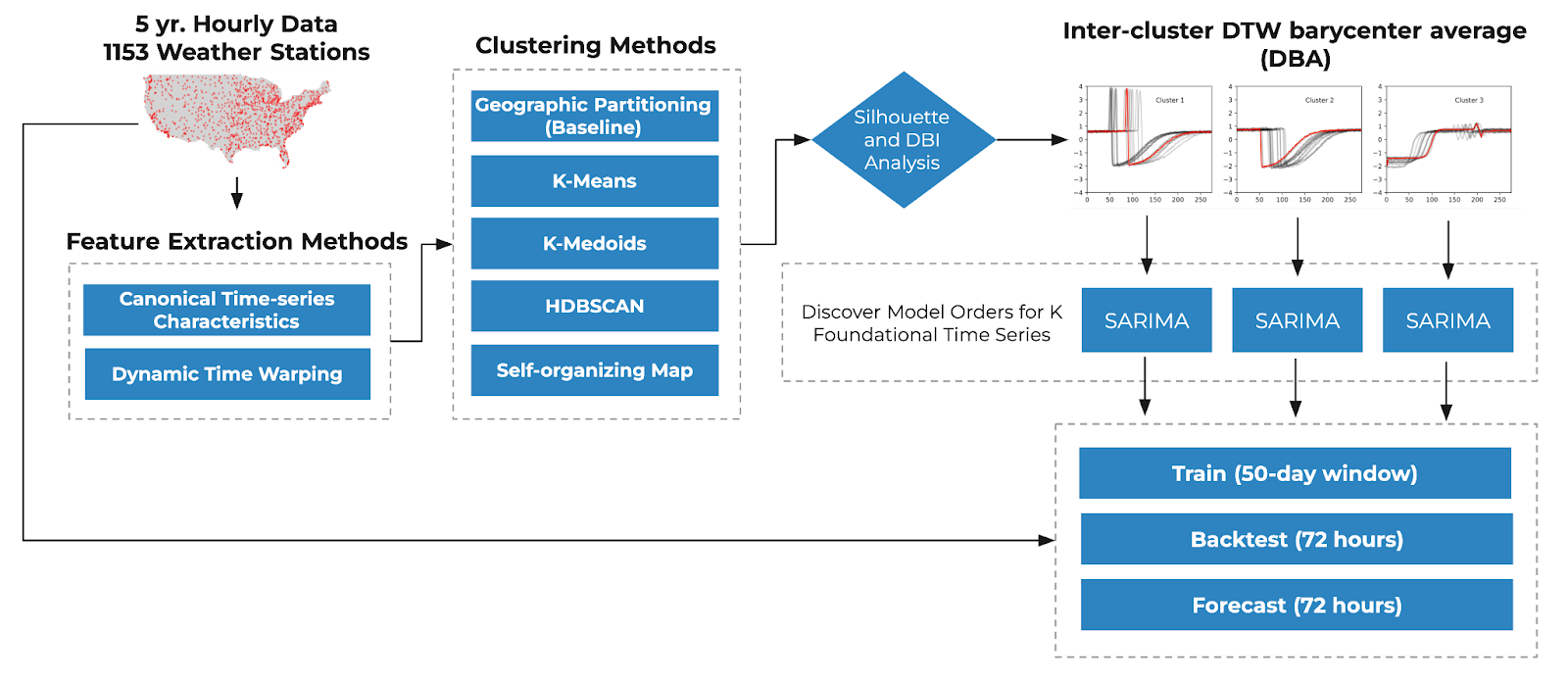
On-site WUE Forecast Methods
We analyze five years of hourly onsite WUE data collected from over 1,000 locations across the United States. Rather than relying on expensive, location-specific models, we employ time series clustering to group locations with similar patterns and develop efficient cluster-specific models, significantly reducing computational complexity. Our approach explores a combination of advanced clustering techniques, including shape-based methods like Dynamic Time Warping (DTW) and feature-based methods leveraging canonical time-series characteristics (Catch22). These are paired with partitional, density-based, and neural network-based clustering algorithms such as K-Means, K-Medoids, HDBSCAN, and Self-Organizing Maps (SOM).
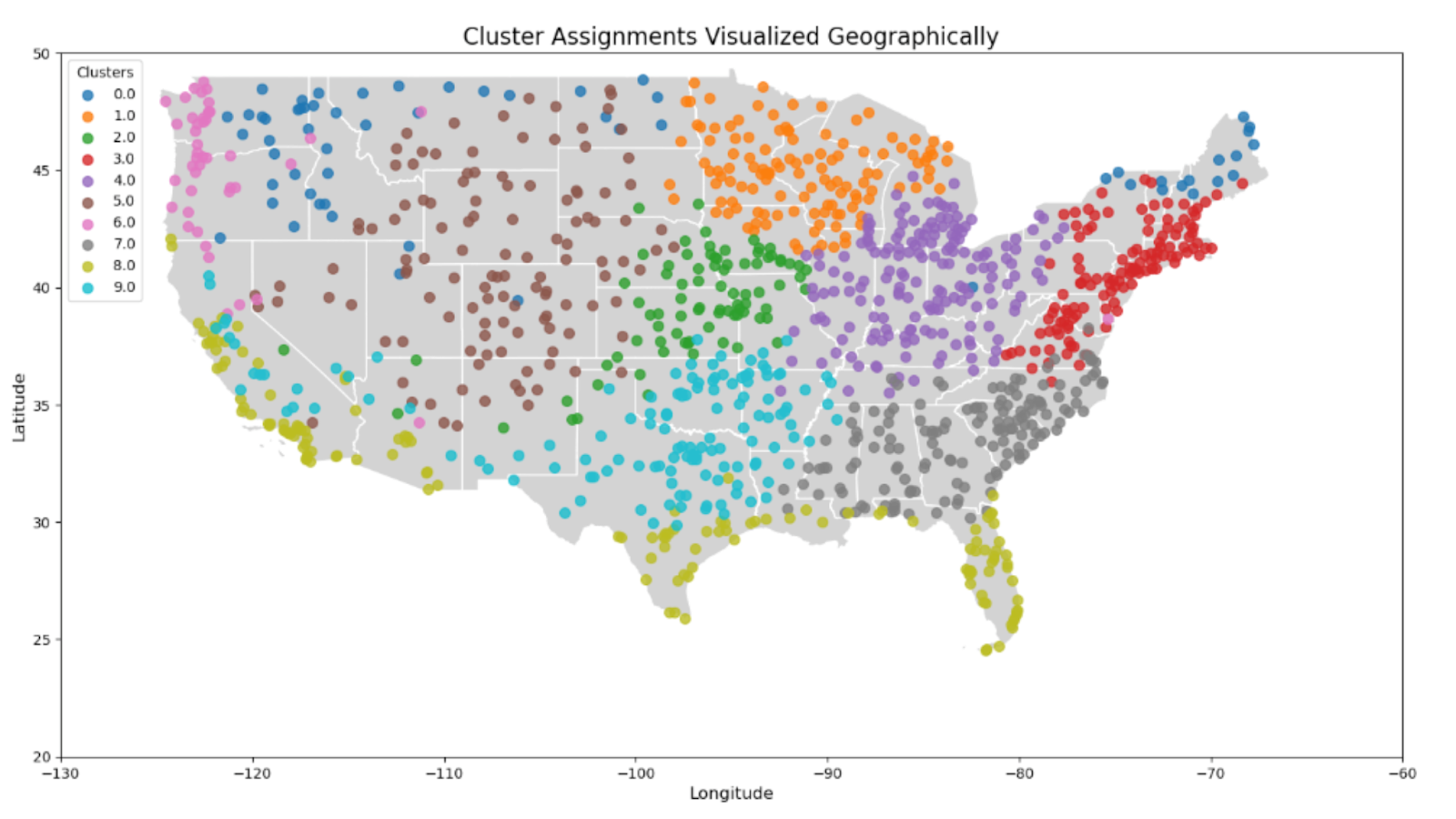
Cluster Assignments Visualized Geographically
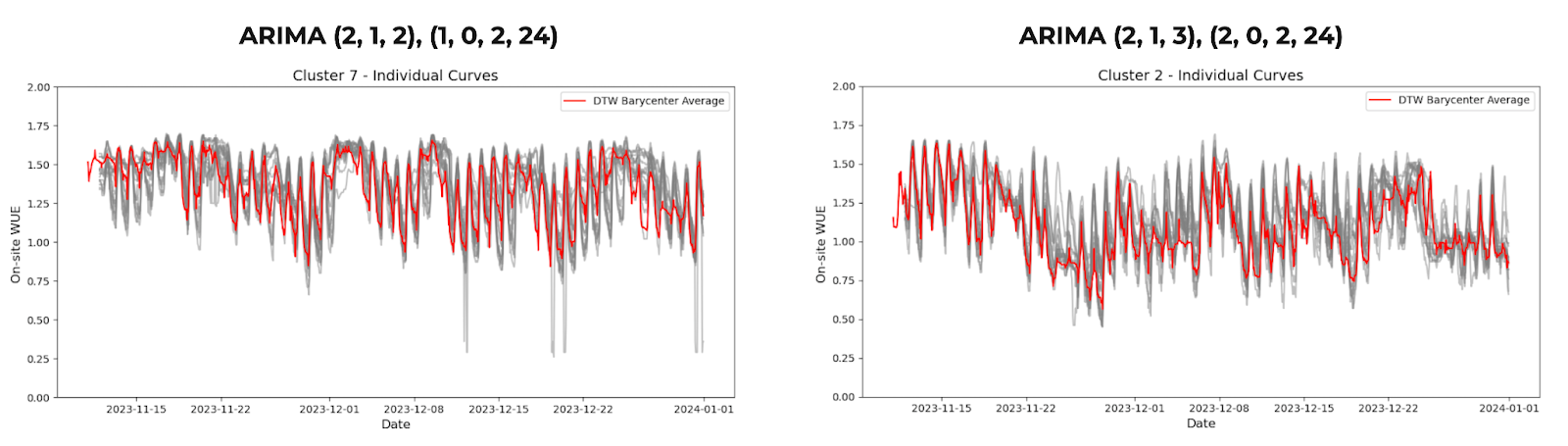
Example Clusters and their DTW Barycenter Averages (DBA)
To represent each cluster, we compute a representative time series using the Barycenter Average and implement SARIMA models to deliver accurate and efficient forecasting. This innovative, multilevel modeling approach uncovers meaningful patterns across diverse locations, ensuring both scalability and cost-effectiveness. By adopting these techniques, we not only optimize forecasting for current use but also establish a robust framework for expanding our product to other geographies.
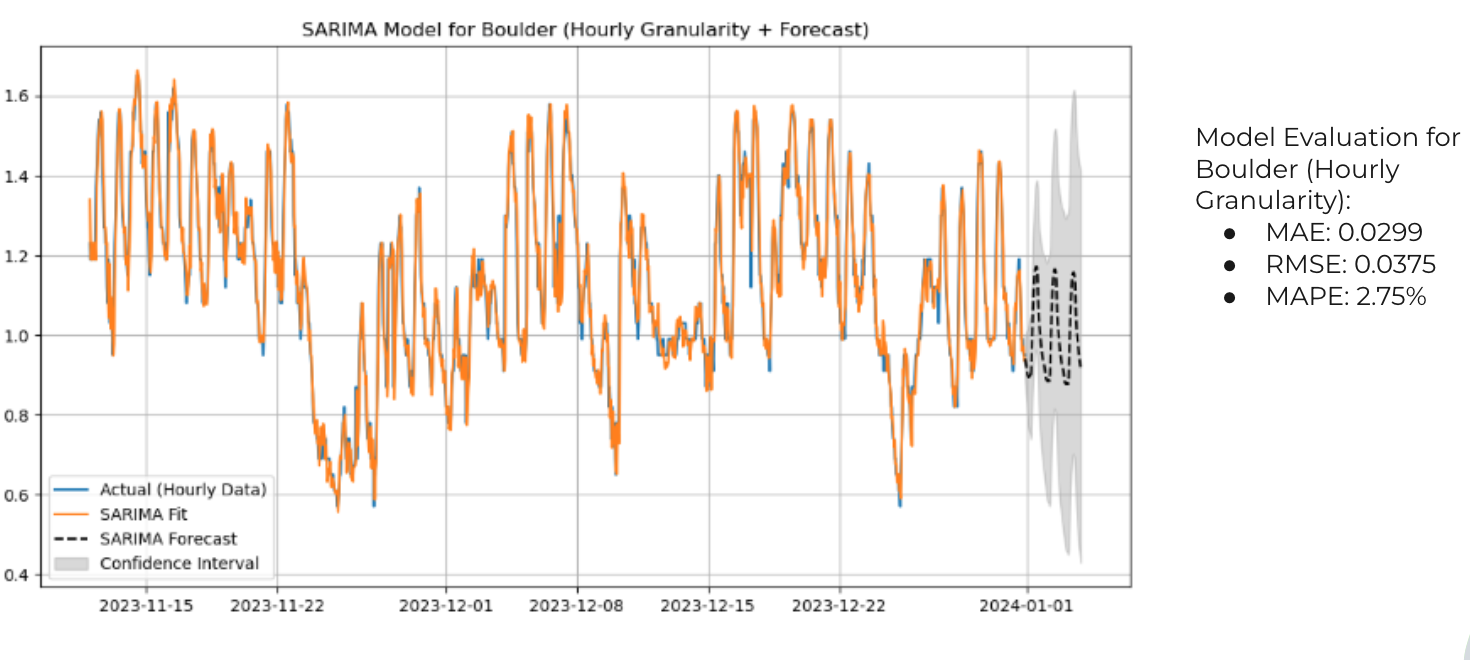
SARIMA model forecast for on-site WUE in Boulder, CO (MAE: 0.029, RMSE: 0.038, MAPE: 2.75%)
Due to computational limitations, we chose to discover the SARIMA model order with auto/data-determined weights from the barycenter averaged time series for each cluster, then fit the models to each city for city-level forecasting results for on-site WUE. Overall, across all models for each city, we achieved an average MAPE of 11.14%, slightly above a benchmark of 10% or below (standard for time series evaluation in industry).
Key Learnings
The primary takeaways from this project were the insights we gained speaking to various subject matter experts with respect to computational sustainability. The validation of our focus on water and energy challenges has reinforced the urgency of this work, particularly given the staggering growth in data center capacity and the severe constraints on power grids and water resources. We discovered that access to workload and compute scheduling data is highly sensitive. Furthermore, water utilization data is even scarcer than energy data, with availability varying widely depending on the cooling systems and geography. Having to rely on simulated data from a previous study, we gained substantial experience in reproducing research and extending results to tailor towards our project’s needs. Additionally, we expanded our knowledge of working with AWS and designing our own data architectures.
Our Contributions & Impact
WUE metrics are highly spatially and temporally variable and propose a significant challenge to predict with high accuracy and computational efficiency. Our work contributes toward developing the large-scale forecasts necessary for analyzing water sustainability in data centers. In tackling both the on-site and off-site WUE forecast methodologies, we have explored three complex forecasting models (SARIMA, TimesFM, and an LSTM), evaluated various novel weather clustering methodologies, and created an interactive and simple web app to display our results in an accessible and impactful manner.
We hope to share our results with a few key parties:
- The team at UC Riverside that contributed to the dataset for water sustainability, whose methodology we drew from heavily. They were interested in our work with the data and were keen to see how we might be able to optimize water usage efficiency in data centers.
- Data center operators who we have interviewed during the initial stages of our project and whose feedback we kept in mind while designing the project.
- An advisor associated with water use research that impacts EPA policy and state regulations.
Future Works
- Live Forecasting: We propose a key expansion of the project into incorporating live data feeds for weather and energy mix to ensure that our work continues to be useful for data center operators. We consider live forecasting by streaming data from these data sources, or batch forecasting by periodically updating our data and models.
- Improved Forecast Performance: We also want to refine on-site WUE simulation to accommodate varying operational scenarios and bolster off–site WUE methods by investigating additional data sources and multivariate forecasts.
- Long Term Water Resilience: Our progress towards more computationally efficient WUE forecasts will be essential for sustainable data center planning. The construction of data centers involves significant fixed costs, with power and water availability as critical considerations in site selection. Accurate projections of WUE over 15-30 years can provide valuable insights into the sustainability of water resources in prospective locations. Such forecasts must also address ethical imperatives, including equitable water access and the consideration of which communities would be affected the most. By integrating these dimensions, decision-making tools can promote sustainable growth by balancing industrial needs with broader societal responsibilities.
- Outreach: Lastly, we want to pay adequate attention to ethical concerns by leveraging our insights to increase public awareness about the impact that data center resource overconsumption has on communities’ water supplies.
Acknowledgements
We extend our sincerest gratitude to Shaolei Ren, Pengfei Li, and their team at the University of California—Riverside, whose input, methodology, and data we used to design our own processes.
Additionally, we express our appreciation for various industry experts, including Ivy Chan, Ivan Benitez, Arjan Westerof, and Michael Gramani at Equinix, as well as Jim Gao at Phaidra. Their domain insights and direct feedback were instrumental in deepening our understanding of the data center space.
We also deeply thank our capstone instructors, Joyce Shen and Morgan Ames, for their continued guidance and mentorship throughout this project.
References
Beveridge, Nathaniel R., "Deep Learning for Weather Clustering and Forecasting" (2021). Theses and Dissertations. 5082. https://scholar.afit.edu/etd/5082
Eure, J. (2024, April 24). The world’s AI generators: Rethinking water usage in data centers to build a more sustainable future. Lenovo StoryHub. https://news.lenovo.com/data-centers-worlds-ai-generators-water-usage/
Privette, A. P. (2024, October 11). Ai’s challenging Waters. Grainger Engineering Office of Marketing and Communications. https://cee.illinois.edu/news/AIs-Challenging-Waters
Gupta, P. S., Hossen, M. R., Li, P., Ren, S., & Islam, M. A. (2024). A dataset for research on Water Sustainability. The 15th ACM International Conference on Future and Sustainable Energy Systems, 442–446. https://doi.org/10.1145/3632775.3661962
Li, P., Yang, J., Islam, M. A., & Ren, S. (2023). Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models (Version 3). arXiv. https://doi.org/10.48550/ARXIV.2304.03271
Lubba, C. H., Sethi, S. S., Knaute, P., Schultz, S. R., Fulcher, B. D., & Jones, N. S. (2019). catch22: CAnonical Time-series CHaracteristics. Data Mining and Knowledge Discovery, 33(6), 1821-1852.
Mishkin, N. (2024). Mastering MAPE: How to Explain Forecast Accuracy to Your Boss and Improve Sales Predictions. https://medium.com/@Behavior2020/mastering-mape-how-to-explain-forecast-accuracy-to-your-boss-and-improve-sales-predictions-657f6a9f399b
Peer, R. A., Grubert, E., & Sanders, K. T. (2019). A regional assessment of the water embedded in the US electricity system. Environmental Research Letters, 14(8), 084014. https://doi.org/10.1088/1748-9326/ab2daa
Rogoway, M. (2023, February 22). Google’s water use is soaring in the Dalles, records show, with two more data centers to come. oregonlive. https://www.oregonlive.com/silicon-forest/2022/12/googles-water-use-is-soaring-in-the-dalles-records-show-with-two-more-data-centers-to-come.html
Srivathsan, B., Sorel, M., & Sachdeva, P. (2024, October 29). AI power: Expanding Data Center capacity to meet growing demand. McKinsey & Company. https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/ai-power-expanding-data-center-capacity-to-meet-growing-demand
Tingström, C., & Åkerblom Svensson, J. (2023). Forecasting With Feature-Based Time Series Clustering (Dissertation). Retrieved from https://urn.kb.se/resolve?urn=urn:nbn:se:hj:diva-61877
More Information
