


")
")


")


Pawpulation Forecast
Problem & Motivation
Animal shelters have limited resources, making it critical to optimize care for animals without a home and under their care temporarily. Knowing approximately how long animals will be in a shelter’s care would help animal shelters make better decisions on resource allocation and intervention efforts to aid adoption. However, animal shelters struggle with accurately predicting this information early due to their limited knowledge about the animal at intake. Pawpulation Forecast integrates directly with shelters’ data APIs to provide animal shelters with a length-of-stay prediction report for each animal that is in their care, using a minimal set of features routinely collected as part of the intake process.
Data Source & Data Science Approach
For this project, we use XGBoost modeling to predict the length-of-stay bucket an animal will fall into based on limited information collected from the animal during a typical intake process and/or as care is provided post-intake. These length-of-stay buckets were decided in consultation with animal shelter staff and align with major timeline milestones animals encounter during their shelter stay.
We used publicly available animal shelter intake and outcome data from Sonoma County as our primary dataset for model training and MVP API integration. Similar intake and outcome data from other locations including Denver and Austin were used as secondary datasets exclusively to evaluate generalizability of the model trained on Sonoma County data. These datasets represent manually collected intake and outcome information of animals under care at the shelter in the past 11 years. In total, we are using 205,130 animal intake and outcome records that were manually entered, stored and maintained within these animal shelter data management systems. Featuring engineering was also performed on these datasets to improve model accuracy and robustness. Each animal was assigned a length-of-stay label based on how many days they were at the animal shelter to enable model training. In addition, new features were developed by scraping keywords, embedding notes, and summarizing dates .For example, we embedded the Breed column using GloVe to extract more meaning. We then took the embeddings and reduced the dimensions using Principal Component Analysis or PCA and used KMeans to find the clusters of the data. This was repeated for color and Intake subtype columns. In total, our dataset includes 10 numerical attributes and 14 categorical features from each animal record.
Evaluation
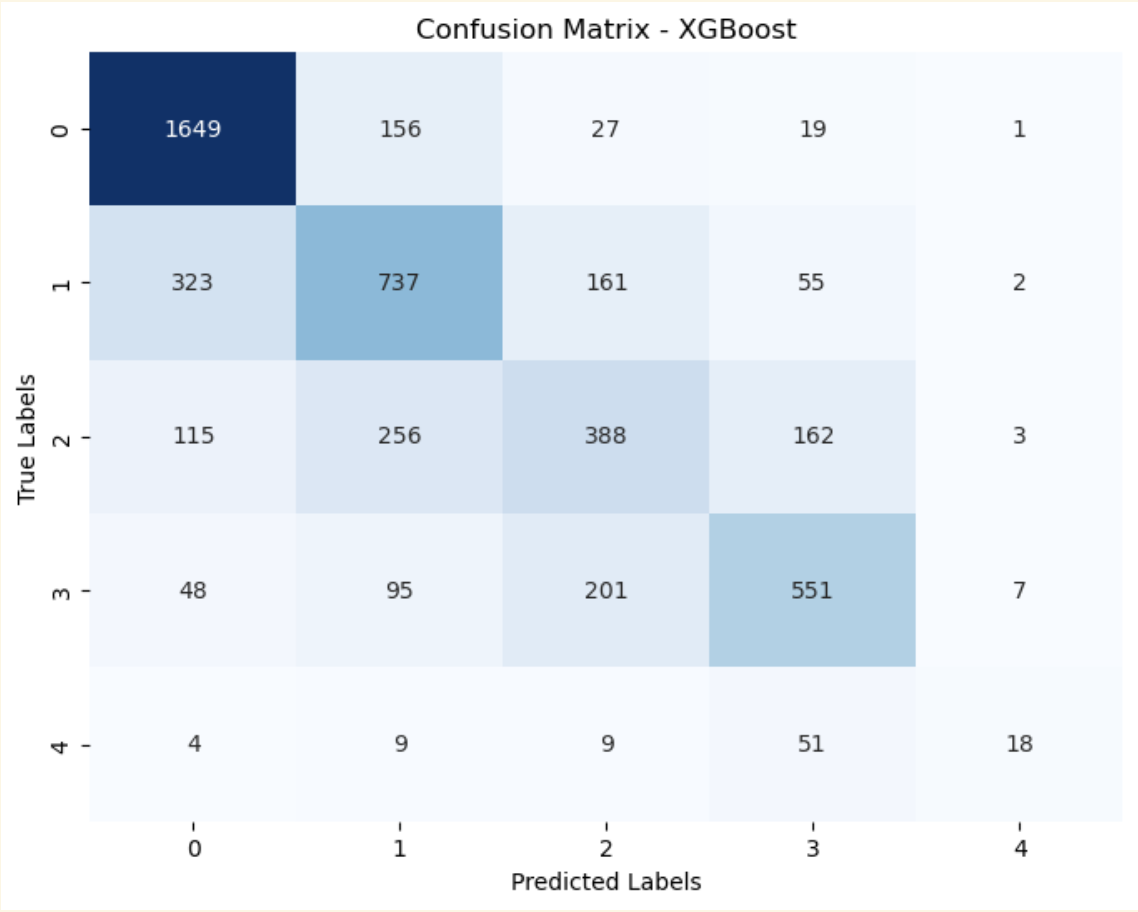
To evaluate our models, we use accuracy scores, classification reports, and confusion matrices to understand the performance of our classification models. You can find some of our model results below:
Sonoma Animal Shelter (XGBoost: 0.66 accuracy, 0.56 f1-score)
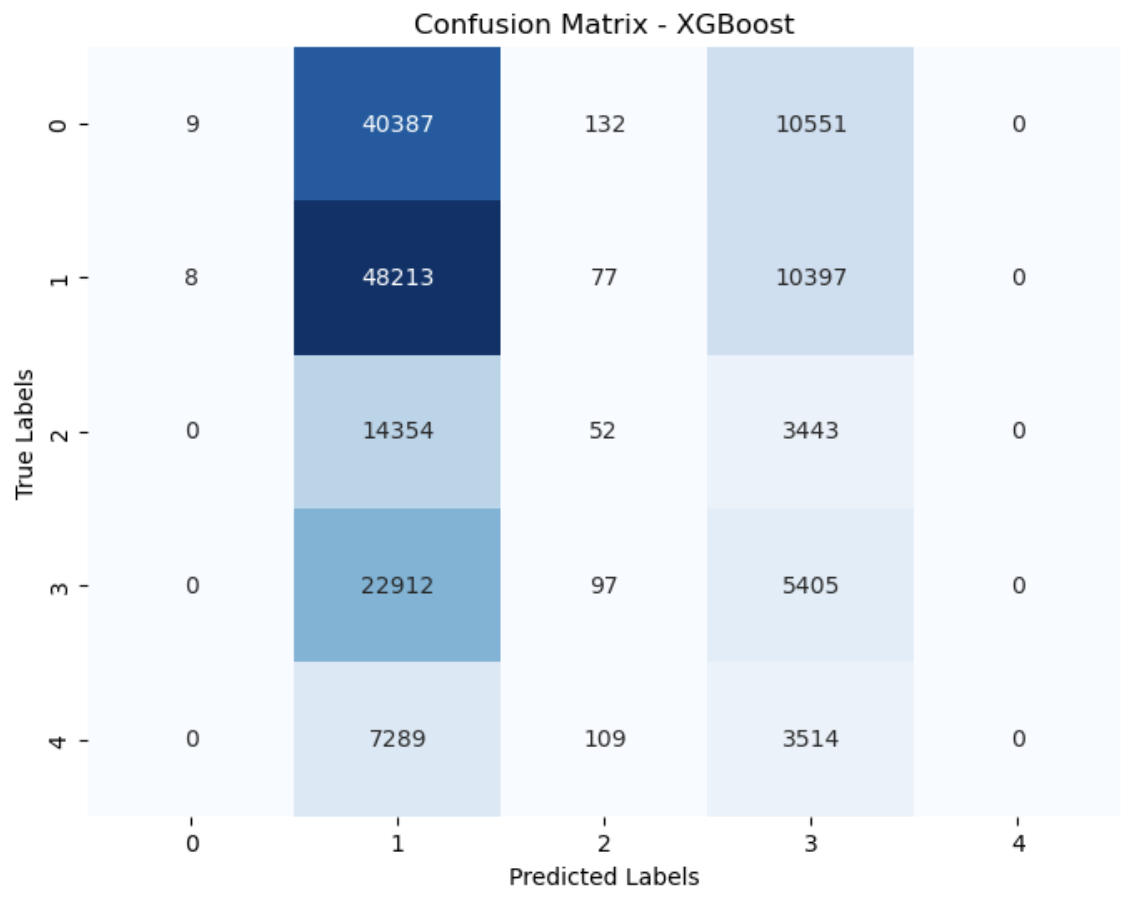
Austin Animal Shelter (XGBoost: 0.32 accuracy, 0.14 f1-score)
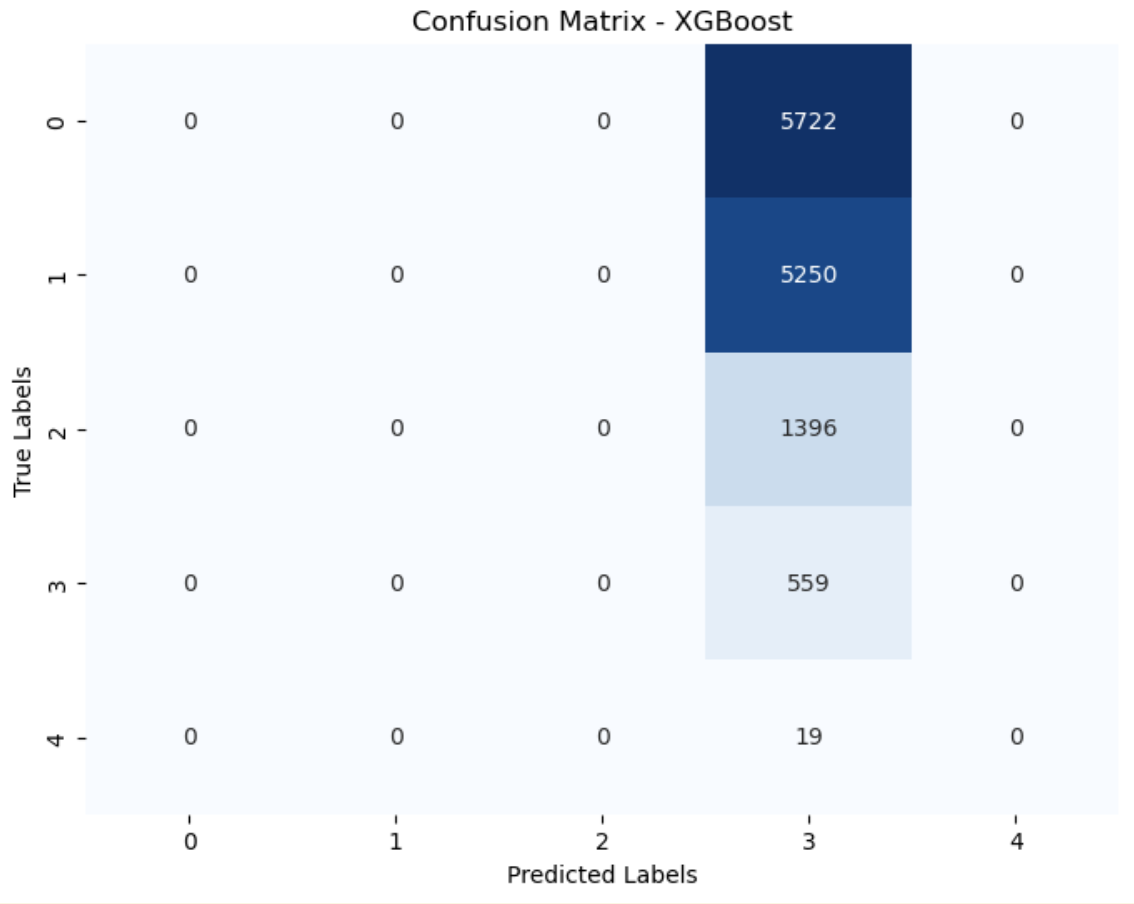
Denver Animal Shelter (XGBoost: 0.04 accuracy, 0.02 f1-score)
Key Learnings & Impact
We aimed to find the best approach for our length-of-stay prediction model. Not many academic papers had similar approaches to build upon, but some work has been published to solve a similar problem with similar data. For example, Bronzi et al developed an outcome prediction model (https://www.causeweb.org/usproc/eusrc/2020/program/8) using similar intake and outcome data from an Austin animal shelter. Their application intent was the same: help animal shelters make better decisions for animals at intake. However, their model predicts animal outcomes (i.e. adopted, transferred, died) and our model predicts the number of days an animal will remain at a shelter in the form of bins that represent length of time ranges. We believe our approach is more useful to animal shelters because it enables iterative decision making overtime.
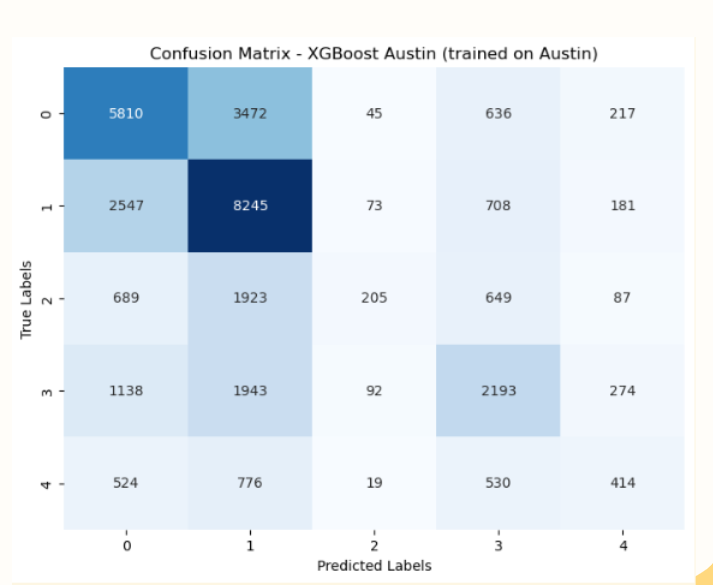
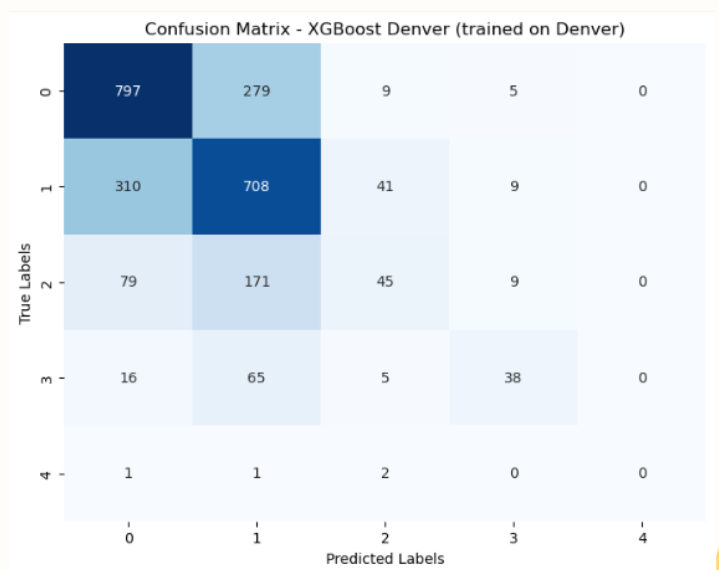
To develop our solution, we compared and tested models that included: Logistic Regression, Random Forest, Gradient Boosted Trees, and XGBoost. XGBoost outperformed the other models, but still had relatively low generalizability across shelters. To address these imperfections, we recommend training and developing a model for each shelter given data set inconsistencies and feature importance differences across shelters. When we tested this theory, model performance improved by +.57 accuracy and +.37 f1-score for Denver Shelter once trained on the Denver data set and by +.19 accuracy and +.24 f1-score for Austin Shelter once trained on the Austin data set.
Austin Shelter w/ Customized Training (XGBoost: 0.51 accuracy, 0.38 f1-score)
Denver Shelter w/ Customized Training (XGBoost: 0.61 accuracy, 0.39 f1-score)
Acknowledgements
We are grateful for the guidance and encouragement of our Capstone Advisors, Dr. Korin Reid and Dr. Puya H. Vahabi, of the Masters in Data Science program at School of Information, University of California, Berkeley.
In addition, the following subject matter experts contributed heavily during the research and/or prototype testing phases of our project:
- Monica Dangler, Director of Pima Animal Care Center (PACC)
- Kaitlyn Pappas, PACC Pet Support Coordinator
- Katie Hutchinson, PACC Animal Placement Manager
- Melanie Sobel, Director of Denver Animal Protection
- Sarah Siskin, Adoption Manager, Humane Society of Memphis
- Joscelyne Thompson, Intake Manager, Humane Society of Memphis
Finally, we acknowledge the contribution of ChatGPT in coming up with our team’s project name.
Course
Data Science 210. Capstone , Summer 2024More Information
